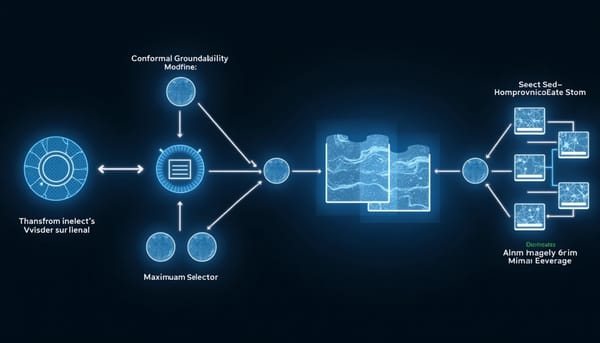
速報 SAVER:選擇性視覺介入的多模態資訊擷取新架構 社群貼文常附多張圖片,但影像與文字關聯薄弱或具誤導性,導致「始終啟用」的多模態融合浪費運算並放大錯誤視覺線索。研究提出SAVER,一套對命名實體辨識與關係抽取僅在必要時啟用視覺證據的框架。SAVER以Conformal Groundability Gate判定字串或實體對的視覺可依據性,並以一種校準程序設定觸發門檻;