
深度分析
單階段稀疏檢索(SSR)以稀疏自編碼取代 K‑means 的多向量檢索新方案
多向量檢索精度高,但需大量記憶體與聚類成本。研究提出單階段稀疏檢索(SSR),以稀疏自編碼取代 K‑means,使用倒排索引。實驗顯示索引時間縮減 15 倍、檢索延遲減半,且效能超越現有基準。在 BEIR 基準測試中,nDCG@10 提升 2.2%,檢索延遲僅 17.5 毫秒。

深度分析
隨著AI生成內容普及,研究以CoCoLoFa資料集的邏輯謬誤評論測試不同來源標籤對判斷的影響。結果顯示,人類在標示為人類或人類+AI時更易接受謬誤,而大型語言模型對來源標籤影響較小,顯示人機協作可減少此類偏誤。本研究招募505名參與者,測量信任與評分。

深度分析
Meta AI客服機器人在2026年6月被駭客利用,透過指令更換帳號恢復電郵並重設密碼,導致多位名人與機構帳號被盜。漏洞源於恢復流程缺乏多因素驗證與外部授權門檻,安全團隊無法偵測。此事件凸顯AI代理人設計的信任邊界問題,呼籲企業加強恢復路徑的驗證與審計。

深度分析
隨著大型語言模型與視覺語言模型在開放式研究上的應用提升,Ptah以多代理與視覺工作記憶結合規則與LLM驗證,實現從查詢規劃、證據收集到報告撰寫的全流程驗證,實驗顯示其報告可信度與視覺呈現優於現有基線,此框架同時提供PtahEval評估協議,量化圖像內容與多模態排版品質,為未來AI法醫與產業應用奠定基礎。
深度分析
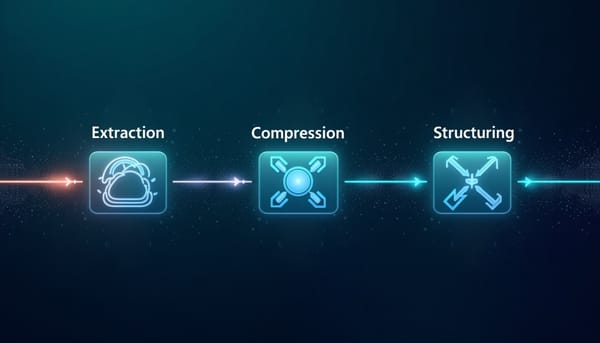
隨著基礎模型規模突破兆參數,傳統的標量蒸餾已無法有效傳遞知識。LoopFM透過將歷史嵌入結構化為VM輸入特徵,開啟高頻寬通道,於公開基準提升AUC超過6%,並在產線將轉換率提升最高1.22%。此框架含抽取、壓縮與結構化三階段,無需即時推論,解決特徵落差與頻寬瓶頸。

深度分析
研究聚焦於結合結構化提示優化與強化學習,打造可解釋的文字分類模型 eXTC。透過三階段學習,先生成規則書 (SOP),再以大型教師模型蒸餾至小型模型,最後利用 RL 改善未覆蓋案例。實驗顯示在多領域基準上,eXTC 同時提升分類精度與解釋品質,並有望推動 AI 透明化。

深度分析
面對JEE、NEET等競賽考試的高階符號推理需求,團隊以強化學習後訓練開源20億參數模型,打造Aryabhata2。模型在考試與跨領域推理基準上超越基礎模型,產出字元減少六成,提升部署效率。此方法結合嚴格答案驗證與難度感知課程,證實在資源受限環境下仍能提升正確率,預示開源模型在大規模教學平台上具競爭力。

深度分析
2026年6月MetaAI客服機器人被駭客利用,直接要求更換Instagram帳號的電子郵件,導致包括奧巴馬白宮帳號在內多個帳號被盜。此案凸顯AI代理人在安全防護與功能便利間的衝突,提醒業界在推廣前必須加強風險測試。專家指出AI代理人缺乏安全防護,業界需在功能與防護間取得平衡。

PMB
PMB為AI程式編寫代理提供本機持久記憶,採用ModelContextProtocol並支援SQLite與多語言檢索。其在LoCoMo基準測得94.5%recall@10、約70 ms延遲,且無需雲端或API金鑰。此技術提升開發者資料主權與效能,可能推動台灣本地AI開發走向去中心化。

Claude Code
GitHub 上的開源專案 caveman 為 Anthropic Claude Code 提供一套讓模型以原始簡潔語句回覆的技能,據稱可削減約 75% 的輸出 token,同時保持技術正確性。專案以 JavaScript 撰寫,採 MIT 授權,支援多種精簡模式,並提供安裝指引與效能基準。

OmniRoute
因Anthropic收緊Claude存取,開發者尋求替代方案。OmniRoute以RTK與Caveman壓縮、177供應商聚合,提供單一端點與自動後備。此專案降低token成本並提升多模型彈性,可能改變台灣AI開發工作流。同時採用MIT授權,支援桌面與PWA介面,讓本地部署更易上手。

Model Context Protocol
MCP讓開發者能以簡易步驟建置AgenticAI與生成式AI代理,結合LangChain、CrewAI等工具,支援向量資料庫與Docker部署,快速落地應用。跨平台、低配需求、開源MIT授權,適合團隊快速驗證AI工作流。同時支援向量資料庫如ChromaDB、FAISS與Pinecone,降低資料檢索。

Cocada 是一套以聊天驅動的多大型語言模型(LLM)協作框架,透過不同模型分工完成規劃、編碼、審查等工作,降低 token 消耗並提升交付品質。該專案在 GitHub 上獲得顯著關注,24 小時內星標快速上升,顯示開發者對多模型協同自動化的需求。

Lucarne在GitHubTrending快速竄升,提供零侵入的本地AI代理遠端管理。透過Telegram或WeChat即時通知、QR碼快速授權,讓開發者可在手機上批准或回覆代理請求,提升工作流靈活性。同時支援多平台部署與低記憶體佔用,適合本地化開發環境。

開發者在開源Java測試框架jqwik1.10.0版加入隱藏指令,利用提示注入欲讓AI編碼代理刪除測試與程式碼。指令透過ANSI控制序列隱蔽,未警告使用者。此舉引發資安與倫理爭議,開發者社群呼籲更嚴格的AI代理治理,此事件突顯AI工具在開源生態的治理盲點,也促使業界重新檢視安全防護機制。

Mozilla 近期公開使用 Anthropic Mythos 搭配自製 Agent Harness,於兩個月內於Firefox原始碼發掘271項安全缺陷,誤報率極低,顯示AI結合專屬測試管線或將提升漏洞自動化發現的可信度與效率。此舉對資安產業與開源社群的長遠影響值得關注。

Anthropic公布5月80%產線程式碼由ClaudeAI產出,藉由自動化編碼代理人從聊天輔助升級為全自主寫程式,導致每位工程師每季交付量提升8倍,同時也帶來代碼審查與安全治理新挑戰。此舉顯示AI代理人已成為企業開發新基準,亦引發安全與職場文化的深層討論。

Poke 這家新創在 3 月推出的 AI 代理人,現在成為首個獲 Apple 核准能在 iMessage 商務訊息平台上運行的 AI 代理人。該服務原本支援 SMS、Telegram 與 WhatsApp,現在加入 iMessage 後,使用者只要以文字對話即可安排日程、管理行事曆、追蹤健康、控制智慧家庭與編修相片。

NVIDIA 於 2026 年 6 月推出 Nemotron 3.5 內容安全模型,結合 4 億參數的多模態與跨語言能力,支援圖片、文字與回應的同時判斷。新模型加入客製化政策規則與可審核的推理追蹤(THINK 模式),並以 Google Gemma 3 為基礎,透過 LoRA 進行安全微調,適合 8GB 以上 GPU 即時部署。

隨著代理系統在多雲環境中大量使用者自訂編排程式碼,信任與授權管理變得難以一致驗證。Grimlock利用eBPF強制所有沙箱流量經過守護代理,並結合TLS 1.3後置驗證與kTLS資料平面,產生短命範圍令牌以實現最小權限委派。實驗證明此架構在不改變應用程式碼的情況下,提供可審計的跨雲代理通訊,提升安全與效能。
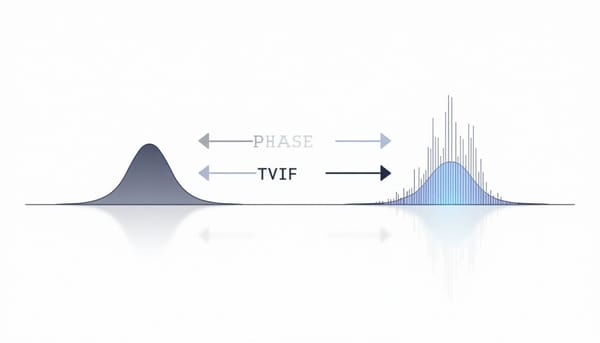
研究指出傳統變分自編碼器(VAE)使用高斯解碼器與 Lipschitz 限制的神經網路,無法生成重尾分布。作者以馬可夫鏈為基礎的相位類型(Phase‑Type)分布取代高斯解碼器,保持編碼器與訓練流程不變,能精確逼近任意正值分布,包括重尾族。
研究指出大型語言模型在多選題中易因干擾選項產生偏好不穩定。提出Inclusion‑of‑Thoughts透過自我過濾僅保留可信選項,減少認知負荷。實驗顯示在算術、常識與教育基準上提升數百分點,且計算成本低。相較於自我一致性或大量抽樣,IoT僅需三階段即可穩定預測,預示未來可於AI服務中廣泛部署。