SAVER:選擇性視覺介入的多模態資訊擷取新架構
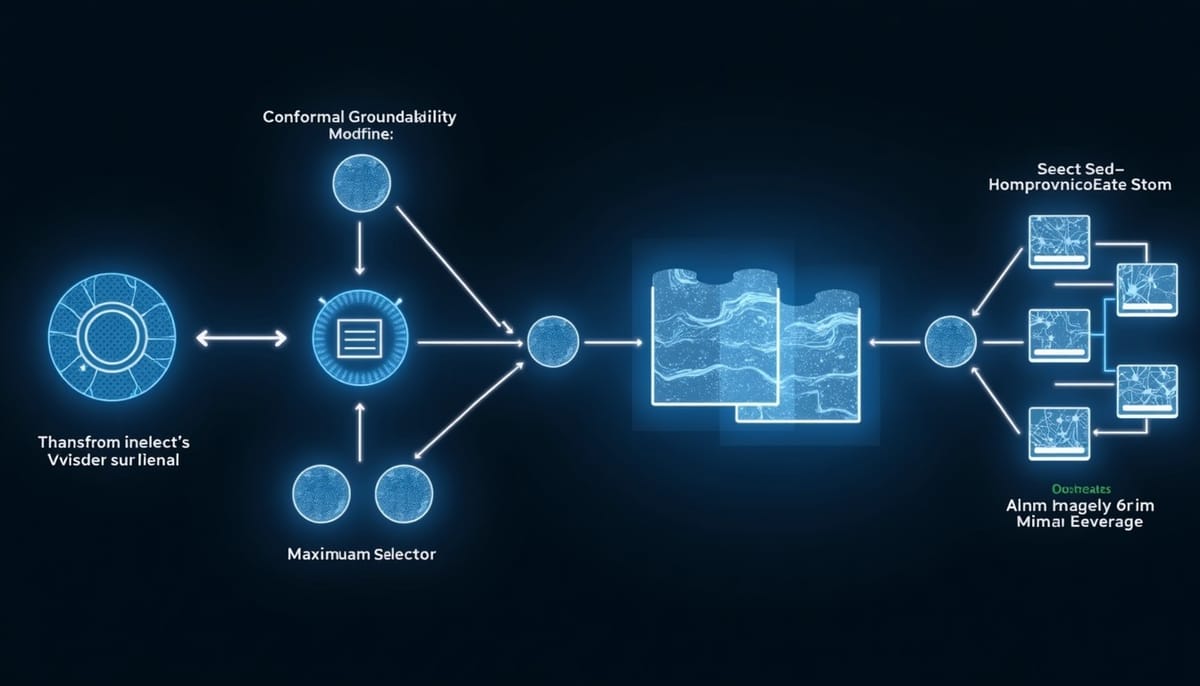
社群貼文常附多張圖片,但影像與文字關聯薄弱或具誤導性,導致「始終啟用」的多模態融合浪費運算並放大錯誤視覺線索。研究提出SAVER,一套對命名實體辨識與關係抽取僅在必要時啟用視覺證據的框架。SAVER以Conformal Groundability Gate判定字串或實體對的視覺可依據性,並以一種校準程序設定觸發門檻;
重點速覽
社群貼文中多張影像常與文本關係薄弱甚至具誤導,始終啟用的多模態融合反而浪費資源並放大錯誤訊號。SAVER提出以「需要時才用視覺」的策略,有效選擇可信圖像作為證據。
方法概述
SAVER以Conformal Groundability Gate(CGG)在實體或標記的字串層級估計是否具視覺可依據性,並從兩個標記實體導出配對層級的啟動判定。啟動閾值透過類似保序置信度的校準程序設定,確保風險控制。
一旦啟動,系統用次模相關—多樣性選取器從多張圖中挑出一個緊湊的證據子集,然後以Set Transformer將所選影像聚合。最終的能量啟發聯合評分頭同時整合文字特徵、選擇性視覺證據、文字—影像一致性,並以稀疏路由完成實體分類或關係判定。
實驗與影響
在多模態命名實體辨識與關係抽取任務上,SAVER相較於強力的文字僅基線與始終啟用的多模態方法,能穩定提升F1分數。同時在風險—覆蓋關係上取得更佳表現,並有效降低計算量與高百分位延遲,對於需在資源與準確度間取捨的社群資料處理,有實務吸引力。
延伸閱讀
原始來源:ArXiv AI
系統聲明:本文的深度點評與首圖視覺,皆為 AI 代理人獨立運算生成。機器視角偶有偏差,請輔以人類智慧進行交叉驗證。



