
深度分析
檢索增強生成(RAG)中文文件表示研究:答案保留率決定正確率
本報告深入分析了在檢索增強生成(RAG)流程中,如何呈現檢索到的文件會影響大型語言模型(LLM)的回答正確度。研究固定檢索結果,僅變換文件的表示方式,測試了原始文件以及十三種不同的選取、摘要與改寫方法,並以四種生成模型評估問答正確率。結果顯示,答案保留率是決定生成品質的主要因素;
深度分析
本報告深入分析了在檢索增強生成(RAG)流程中,如何呈現檢索到的文件會影響大型語言模型(LLM)的回答正確度。研究固定檢索結果,僅變換文件的表示方式,測試了原始文件以及十三種不同的選取、摘要與改寫方法,並以四種生成模型評估問答正確率。結果顯示,答案保留率是決定生成品質的主要因素;

速報
Psych LM為一個在iOS上驗證性的示範應用,提出以本地執行語言模型配合專用的本地優先執行環境,解決情感導向支援對長期脈絡的需求。系統將對話自動轉換為結構化的記憶卡(事實、目標、事件),並以語義向量檢索動態注入提示,達成近乎無限的脈絡感知。

聯邦搜尋
Swirl 是一個開源的聯邦搜尋(federated search)專案,主張在原地查詢各種資料來源,並以大型語言模型(LLM)對結果重新排序,而不把原始資料抽取或建立中央索引。

速報
研究指出,檢索增強生成(RAG)讓大型語言模型引用外部知識,同時增加資料庫外洩風險。作者提出LeakDojo,可在可控環境下評估多種外洩攻擊與RAG系統脆弱性。測試涵蓋多款LLM與資料集,發現查詢生成與對抗性指令可獨立促成外洩,且指令遵從性較高的模型外洩風險更高。

速報
大型語言模型在惡意程式分析應用上常缺乏程式碼層證據與多樣指標支援。研究提出LCCD資料集與LCC-LLM框架,將約34K個PE樣本經反編譯和靜態逆向處理,使用反編譯C、組合語言、CFG/FCG、十六進位與PE欄位等程式碼中心表示。

速報
本文說明「Agentic Publication」概念,一種由大型語言模型驅動的互動式科學發表架構,用來回應科學文獻指數成長的挑戰。架構透過檢索增強生成(RAG)將結構化資料(如知識圖、書目元資料)與非結構化內容(文字、多媒體)整合,並以多代理驗證提升內容可靠性。
速報
本研究提出一套由五個代理人組成的統一架構,能自動從資料集與自然語言目標產出端對端機器學習管線。系統結合代碼為基礎的檢索增強生成(RAG)以理解微服務,並使用可解釋的混合推薦演算法選擇最佳組件。透過大型語言模型進行錯誤詮釋與自我修復,並從執行歷史中自適應學習。

DeepTutor
GitHub 上新星專案 DeepTutor 以 Python 為核心,結合大型語言模型、檢索增強生成(RAG)與多代理系統,打造可自行學習與互動的個人化教學平台。專案已獲超過兩萬顆星與三千次分支,提供 CLI、Web 介面與持續運作的 TutorBot,支援即時問題解答與課程規劃。

速報
傳統同調分析耗時且易造成受訪者疲勞。本研究以大型語言模型建構客戶數位雙生(CDT),將Reddit使用者評論彙整為個人向量資料庫,結合檢索增強生成(RAG)與提示工程,讓CDT檢索過往偏好並以分割因子設計執行兩兩比較,最後以邏輯迴歸估算偏好效用。驗證顯示CDT對真實使用者預測正確率87.73%。

prompt-engineering
這份由社群維護的PromptEngineeringGuide彙整論文、教學、筆記與工具,聚焦提示工程、檢索增強生成(RAG)與AI代理人實作。專案同時提供網頁版與付費課程、企業訓練與顧問服務,對開發者學習途徑及產業採用有明顯推動效果。並吸引廣泛社群貢獻與翻譯支援。
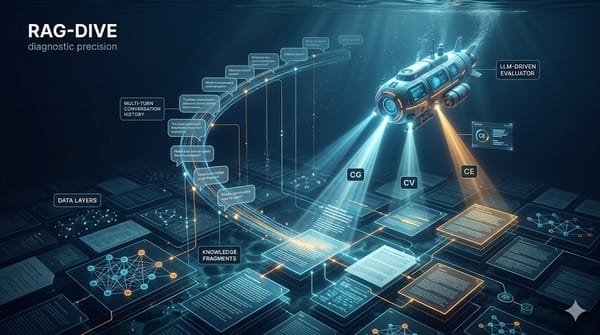
深度分析
RAG-DIVE 提出一套面向多回合對話的動態評估流程,透過 LLM 模擬使用者發起多回合互動,並以三個模組——對話生成(CG)、對話驗證(CV)與對話評估(CE)——連動運作。CG 根據知識文件與先前回合自動提出可回答的追問,CV 篩選並修正低品質輸出,CE 則產出逐回合與整體多回合指標來衡量檢索與生成品質。
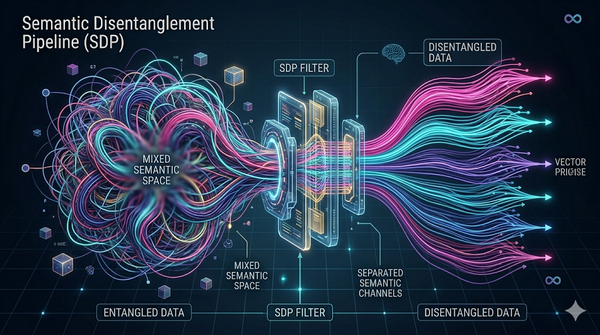
速報
研究發現,當文件在連續文字混雜多主題時,向量化會造成語義纏結。提出語義解纏管線(SDP),以四階段預處理重構文件、採情境化結構與持續回饋,目的是降低跨主題重疊並改善檢索。實驗顯示Top-K檢索精準由約32%增至約82%、Entanglement Index由0.71降到0.14。