
深度分析
Jacobian Lens 揭示 LLM 內部全局工作空間:從可解釋性到對齊安全
研究人員利用新開發的 Jacobian Lens 技術,探索大型語言模型內部的資訊處理機制。該技術可識別模型準備轉化為文字的特徵空間 J-space,發現其功能與神經科學中的全局工作空間理論高度相似,能承載刻意推理與靈活的內部對話。實驗證明透過干預 J-space 可直接改變模型輸出,並揭露其隱藏的策略思考,為 AI 可解釋性與對齊研究提供新突破。
深度分析
研究人員利用新開發的 Jacobian Lens 技術,探索大型語言模型內部的資訊處理機制。該技術可識別模型準備轉化為文字的特徵空間 J-space,發現其功能與神經科學中的全局工作空間理論高度相似,能承載刻意推理與靈活的內部對話。實驗證明透過干預 J-space 可直接改變模型輸出,並揭露其隱藏的策略思考,為 AI 可解釋性與對齊研究提供新突破。

深度分析
聯邦學習旨在保護原始數據,但 5G 網路的實體層調度元數據仍可能洩漏資訊。研究團隊開發 FLINT 框架,透過解碼 PDCCH 調度資訊並將變動識別碼映射回設備,利用多視圖時間建模分析訓練行為,成功從黑盒觀測中推論出模型架構家族。實驗結果顯示其分類準確率極高,證明實體層側信道可將被動偵察轉化為針對性的下游攻擊。

深度分析
AV-JEPA 將 LeJEPA 擴展至音視訊領域,使用早期融合 ViT 與模態丟失實現潛在空間跨模態預測,無需解碼器或對比學習。在 VGGSound 達到 57.1% top-1、AudioSet 32.7 mAP,並支援零樣本跨模態檢索,展現理論引導的簡潔架構潛力。

深度分析
面對前沿 AI 公司安全門檻定義不一導致的驗證困難與競底風險,研究團隊提出一套調和方法論,將各家模糊的風險描述轉化為可審計的量化底線。針對網路與生物濫用風險,透過預期損害模型量化潛在危害;針對自動化 AI 研發,則建立進展速率基準。此舉旨在建立產業統一的最低安全標準,降低風險評估的主觀性並強化第三方審計可行性。
深度分析
Open CoDesign 是一款本地開源的 AI 設計工具,支援多模型與即時產出。它提供桌面原生、可自帶金鑰的彈性,並可匯入 Claude 或 Codex 設定。此工具降低雲端鎖定風險,促進設計工作流程的自主性。同時支援 HTML、PDF、PPTX 等多種匯出格式,適合快速產出行銷素材。

深度分析
現有科學AI模型分散於領域專用模型、工具增強語言模型與科學語言模型,缺乏統一架構。S1-Omni提出一套整合科學數據統一表徵、自然世界知識對齊與領域特定解碼的單一多模態推理模型,能同時處理分子、材料、蛋白質、光譜、科學影像等異質數據,並支援性質預測、光譜到分子生成、蛋白質位點預測、科學影像生成與編輯等任務。

深度分析
行動介面 AI 代理人雖能自動執行複雜任務,但單一錯誤點擊可能造成不可逆後果。SeerGuard 透過指令層篩選與動作層風險評估,利用語意化的世界模型預測後續畫面與安全性,實驗顯示在 Qwen3‑VL‑8B‑Instruct 上將安全效用分數提升至 0.596,風險成本下降至 0.130。

深度分析
深度強化學習策略常被視為黑盒,難以解讀與編輯。本研究提出三階段轉換流程,將 PPO 教師策略萃取為可執行的 Prolog 規則程式,並透過回報最大化編輯使其超越教師。在有限狀態任務中達到精確最優回報,連續控制任務則受維度災難限制,但 CartPole 與 Acrobot 幾乎完全替代神經網路。
深度分析
一項針對4,181道奧數題的研究發現,多智能體系統中專門評審者的錯誤檢測精度雖高(0.861 vs 0.644),但批評被後續答案採納的比例卻遠低於廣播式討論(0.336 vs 0.935),導致最終解題率反而落後。研究指出,評審者精度與批評採納是兩個可獨立測量的維度,設計時須同時關注。
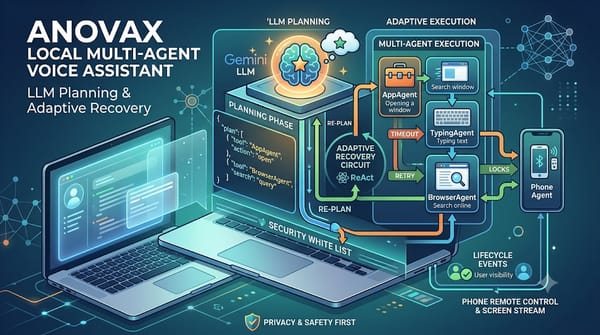
深度分析
隨著語音助理逐漸雲端化,AnovaX 提出本地多代理架構,結合 LLM 計畫、類型化執行器與自適應恢復機制,支援手機遠端控制與即時螢幕串流,實現在筆電上全程離線操作,提升隱私與可控性,同時展示開源方案相較於商業雲端助理的可檢視與安全優勢與開放性。
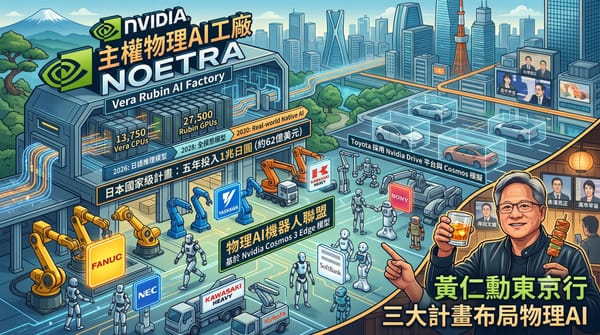
深度分析
Nvidia執行長黃仁勳訪日促成三大合作:Noetra國家AI工廠將於2028年啟用,日本政府投入1兆日圓發展國產物理AI。Fanuc、Toyota等大廠採用Cosmos 3 Edge模型,目標2040年導入千萬台AI機器人,搶佔全球三成市場。
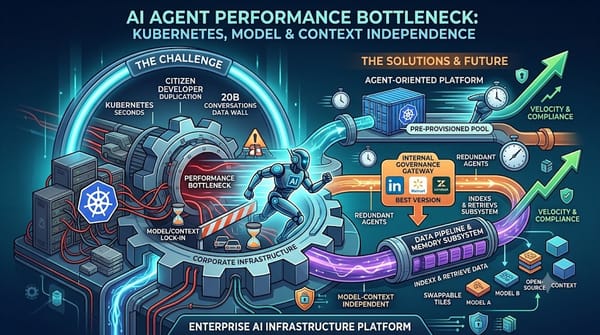
深度分析
LinkedIn、Walmart、Zendesk三大企業發現AI代理效能受限於傳統基礎建設,透過預配置容器、內部治理閘道與強化資料管線等方式提升速度,同時推動模型與上下文獨立化,預示企業未來將更倚賴自建平台而非僅依賴雲端供應商,並加速跨部門協作與安全合規。