
速報
大型語言模型規則蒸餾提升視覺問答推理解釋性
本研究提出一種從大型語言模型(LLM)蒸餾規則的方法,協助視覺問答(VQA)系統在面對新任務需求時快速擴充其邏輯推理模型。研究者以答案集合程式(ASP)作為推理理論的基礎,透過提示 LLM 產生並修正規則,並以少量 VQA 範例驗證與回饋。
速報
本研究提出一種從大型語言模型(LLM)蒸餾規則的方法,協助視覺問答(VQA)系統在面對新任務需求時快速擴充其邏輯推理模型。研究者以答案集合程式(ASP)作為推理理論的基礎,透過提示 LLM 產生並修正規則,並以少量 VQA 範例驗證與回饋。

速報
研究聚焦於教育測驗題目難度預測,提出 Epi2Diff 框架將大型推理模型的推理痕跡轉換為認知情節序列,結合語意特徵以提升預測準確度。實驗顯示在四個真實資料集上均優於現有基線,SAT 測試更獲得 8.1% 的相對提升。結果表明較難題目會產生更迭代且以實作為主的情節動態,證明此方法具可解釋性與實用性。

速報
即時分割(ICS)要求模型僅靠少量參考圖與遮罩,即可在查詢圖上完成目標區域分割,且不更新參數。過往研究多聚焦於精度,忽略了系統在不同參考圖下的穩定性。

速報
研究者針對非線性偏微分方程的求解提出高階光譜卷積,將 Fourier 神經算子從對角調變擴展至 n 線性模式混合,提升對多項式非線性互動的捕捉能力。實驗顯示,HO‑FNO 在高度非線性情境下單層即勝過多層 FNO,且與最新 Transformer 與 State‑Space 模型表現相當或更佳。此成果於 GitHub 開源,促進可重現研究。
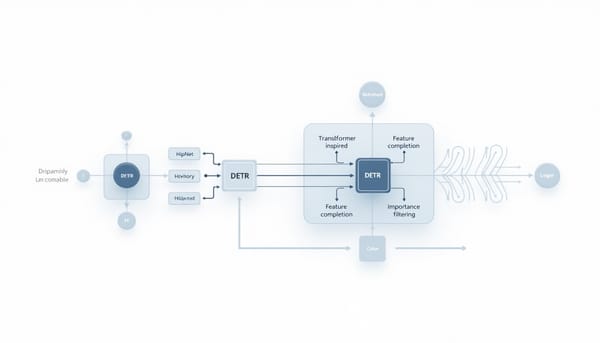
速報
本研究針對現有目標偵測模型缺乏顯式記憶機制的問題,提出 Hippocampus‑DETR,將模擬人類海馬體結構的 HipNet 記憶網路模組嵌入 DETR 架構。模型在訓練時採層級優化策略,形成具備記憶檢索與補全功能的子系統,實現特徵的模式分離、模式完成、重要性過濾與資訊整合。

速報
大型語言模型(LLM)在資料生成與標註上越來越常見,但研究者可透過調整提示詞、解碼參數或輸出格式來進行 p‑hack,導致結果不可靠。研究團隊提出一套預先註冊實驗與可用模型的流程:先在現有模型上確定分析方法,將實驗計畫與未來可接受的模型清單公開登記,然後在登記後首個符合條件的新模型上執行確認分析。

速報
大型語言模型(LLM)代理人在序列決策上表現優秀,但在長期任務中仍屬被動,缺乏「如果」推理的內部世界模型。研究團隊提出將未來感知內化於單一自回歸模型,透過文字化的狀態展開與計畫條件成功估計(類似 Q 值)來模擬未來。

速報
本研究探討隨著雲端、巨量資料與大型模型的快速發展,傳統大型 AI 模型面臨訓練成本高、部署複雜等挑戰,因而轉向輕量、私有與領域專屬模型。為解決異質模型間互動與協作的瓶頸,作者提出「全球 AI 模型網路 (AI-ModelNet)」概念,藉由建立模型間的連結通道,實現能力共享與協同推理。

速報
本研究批判了將人工智慧對齊至單一、聚合的人類偏好之做法,指出不同社會與政治立場會產生截然不同的價值觀,若以此為唯一指令可能導致危險。作者主張 AI 應以不可協商的客觀底線為基礎,包括能力、事實正確性、誠實與合法性,並將多元價值限制於表層語言與合理的價值取捨。

速報
研究者將旋轉位置編碼(RoPE)應用於圖形資料,提出 Wave‑Induced Rotary Encodings(WIRE)透過圖拉普拉斯譜旋轉 token,將結構資訊注入注意力。實驗顯示在合成與真實圖形任務上皆有顯著提升,且在格點上還原為標準 RoPE,漸近與圖形有效阻抗相關,兼容線性注意力。

速報
研究指出,在非結構化環境中建置持續運作的具身代理人,需要同時協調網路 API、物聯網裝置與機械操作,並能自動恢復實體失效。針對現有規劃器缺乏統一的網路‑實體行動空間、上下文膨脹以及開環執行無法偵測失敗等問題,研究團隊提出 OmniAct 框架。

速報
本研究探討開源博弈的連續化模型,提出參數化開源博弈讓玩家以參數向量決策,並透過語意映射產生混合行動。研究發現,在對稱 2×2 博弈中,自利梯度上升的合作門檻可精確計算,且神經語意類別的合作條件由跨玩家敏感度比率決定。結果顯示,開放參數可重塑學習動態,強耦合甚至能促成合作。