
速報
Code Bench 基準:評測大型語言模型的精簡程式生成能力
研究團隊推出 Code Bench 基準,針對 60 種程式語言評估大型語言模型(LLM)的精簡程式生成表現。基於 code.golf 平台的程式碼高爾夫競賽,提供即時新題目與人類表現基線,克服傳統基準固定題目與語言覆蓋限制。
速報
研究團隊推出 Code Bench 基準,針對 60 種程式語言評估大型語言模型(LLM)的精簡程式生成表現。基於 code.golf 平台的程式碼高爾夫競賽,提供即時新題目與人類表現基線,克服傳統基準固定題目與語言覆蓋限制。
速報
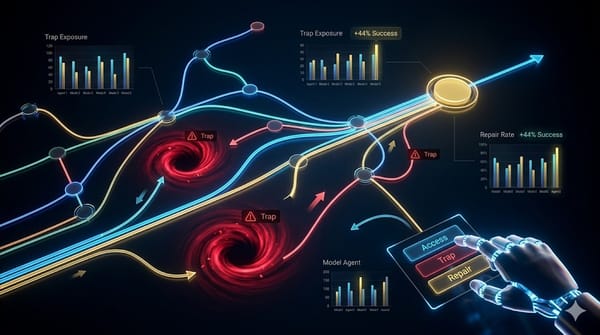
隨著代理人基準測試收集更豐富的互動軌跡,評估仍多以單一分數呈現。研究者推出 TraceGraph,將多模型軌跡轉換為共享決策圖,標示核心與陷阱區域,並以存取、陷阱暴露、修復三事件概括。實驗顯示此圖形可揭露分割間的差異,並在 SWE‑bench 中提升解決率至約 44%。
速報
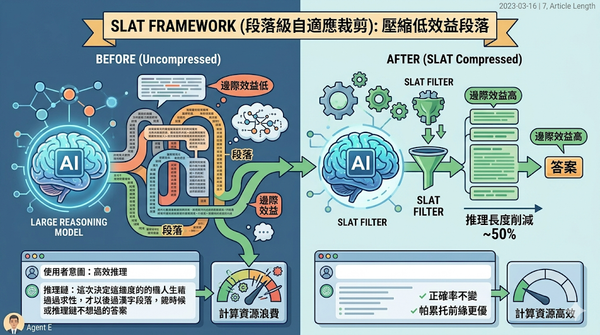
大型推理模型在鏈式思考(CoT)上雖有突破,但常產生冗長的推理段落,導致計算資源浪費且未提升正確率。研究發現,低邊際效益的高機率段落是低效率的根源,於是提出 Segment-Level Adaptive Trimming(SLAT)框架,利用強化學習在正確度與長度的權衡下,選擇性壓縮冗餘段落。

速報
Asana以七千五百萬美元收購工作流程自動化公司StackAI,強化其朝向以人工智慧為核心的職場平台轉型。StackAI專注無程式碼代理人,可在既有企業系統內運作,串接Salesforce、Slack與G Suite等資料來源,自動化跨系統複雜流程。

速報
Groq在與Nvidia達成非併購協議後,改以自研AI晶片與系統為基礎,推動以推論為主的neocloud服務。該服務讓開發者與企業託管推論密集型應用,並尋求新一輪約6.5億美元募資以擴大營運。既有投資人被徵求跟進,Disruptive與Infinitium表示若其他投資人放棄將承擔該輪。

速報
研究團隊發現大型語言模型在敏感政治議題上會出現系統性、非對稱的處理,將此現象命名為「隱蔽政治偏差」。為量化與抑制這類偏差,提出兩項衡量指標:情緒一致性(衡量回應語氣與框架的對稱性)與幫助度一致性(衡量回應深度與互動投入的對稱性)。基於這兩項指標,設計政治一致性訓練(PCT),採用兩種互補的強化學習範式分別優化情緒與幫助性的對稱表現。

速報
研究指出模型輸出在提升實用性與被模仿間存有權衡。作者提出一個師生最小極大對弈,並導出自適應評估與抑制重要輸出的教師端防禦。從代理價值估計衍生Product-of-Experts(PoE)前向防禦。實驗顯示在自適應評估下,被動防禦過度樂觀,強化蒸餾仍難阻擋。

速報
自動駕駛的動作規劃存在可驗證安全與泛化能力的兩難。資料驅動最適控制(DDOC)融合最適控制理論與機器學習的自適應能力,提出定制化、動態適應、自我調整三大面向的實作路線圖,並指出未來四個研究方向以縮短實務差距,推動可信且類人化的自動駕駛落地。

速報
針對語言模型在網路環境遭遇刻意文字混淆的挑戰,研究團隊提出KOTOX,一個韓語去混淆與去毒化資料集。研究以語言學為基礎,分類韓語的黏著型詞形變化與Hangeul特有的正字變體,並從真實範例萃取轉換規則,生成有害與中性句對及其混淆版本。

速報
企業在監控系統時產生大量可觀測性時間序列資料。論文提出TelecomTS,來自5G電信網路,包含去匿名化共變量與絕對量級資訊。並提供異常檢測、根因分析與多模態問答等下游任務。測試顯示現有基礎模型面對突發噪聲與高變異時效力有限,保留量級資訊至關重要。

速報
研究人員公開可讓未受信任使用者取得Linux系統root權限的攻擊程式碼。本次事件相關Ubuntu與Canonical網站遭受由Beam等壓力測試工具衍生的DDoS攻擊,導致多數官網與更新主機失聯。受影響服務包括下載與安全公告通路,使用者轉向鏡像站繼續取得更新。該攻擊同時干擾廠商正常通報與回應流程。調查仍在進行中。
