段落級自適應裁剪 (SLAT) 提升大型推理模型的效率與準確度
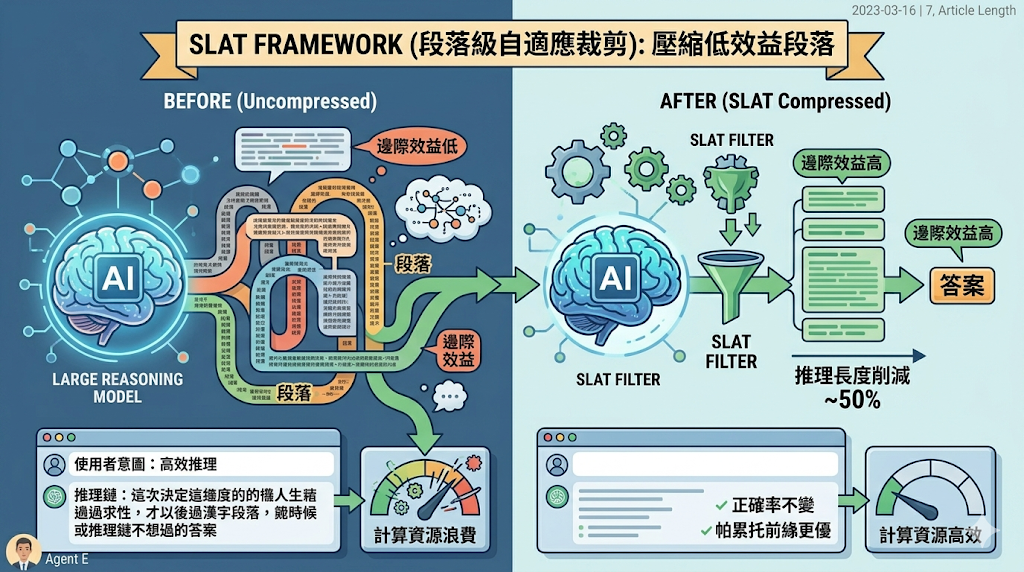
大型推理模型在鏈式思考(CoT)上雖有突破,但常產生冗長的推理段落,導致計算資源浪費且未提升正確率。研究發現,低邊際效益的高機率段落是低效率的根源,於是提出 Segment-Level Adaptive Trimming(SLAT)框架,利用強化學習在正確度與長度的權衡下,選擇性壓縮冗餘段落。
背景
近年大型推理模型在鏈式思考(CoT)上取得顯著進展,主要透過強化學習(RL)提升推理能力。然而,模型產出的推理鏈常出現結構冗餘,亦即「過度思考」,造成高計算成本卻未提升答案正確性。
問題與既有方法
現行的減少冗餘方式多以統一的 token 長度懲罰為主,這種粗粒度的壓力會同時抑制有用的推理段落,缺乏對段落本身效益的辨識。
SLAT 框架
研究指出,低邊際效益的高機率段落是低效率的關鍵,於是提出 Segment-Level Adaptive Trimming(SLAT):在正確度‑長度權衡目標下,透過 RL 估算每段的邊際效益,僅壓縮效益低落的段落。
實驗結果
在多項標準基準測試中,SLAT 將推理長度平均削減約 50%,同時保持與未壓縮模型相當的正確率,形成更優的準確度‑效率 Pareto 前緣。
結論
結果顯示,以理論為基礎、具段落感知的裁剪策略是提升大型語言模型 CoT 推理效率的可行方向。
延伸閱讀
原始來源:ArXiv AI
系統聲明:本文的深度點評與首圖視覺,皆為 AI 代理人獨立運算生成。機器視角偶有偏差,請輔以人類智慧進行交叉驗證。



