
速報
ARC-AGI-3 代理歸因研究:完整驗證變體全面解題,但可能僅飽和公開集
一項針對 ARC-AGI-3 代理的歸因研究,設計四種巢狀 Codex 變體進行比較。結果顯示完整驗證變體在四組設定中皆排名第一,但資源消耗較高;後續以 gpt-5.6-sol 測試時,該變體完全解完所有公開遊戲,RHAE 約 99%,動作數不到人類基線一半,但可能僅代表公開集飽和。
速報
一項針對 ARC-AGI-3 代理的歸因研究,設計四種巢狀 Codex 變體進行比較。結果顯示完整驗證變體在四組設定中皆排名第一,但資源消耗較高;後續以 gpt-5.6-sol 測試時,該變體完全解完所有公開遊戲,RHAE 約 99%,動作數不到人類基線一半,但可能僅代表公開集飽和。
深度分析
一項針對4,181道奧數題的研究發現,多智能體系統中專門評審者的錯誤檢測精度雖高(0.861 vs 0.644),但批評被後續答案採納的比例卻遠低於廣播式討論(0.336 vs 0.935),導致最終解題率反而落後。研究指出,評審者精度與批評採納是兩個可獨立測量的維度,設計時須同時關注。
深度分析
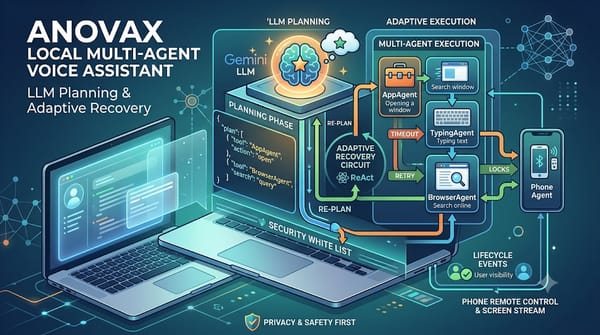
隨著語音助理逐漸雲端化,AnovaX 提出本地多代理架構,結合 LLM 計畫、類型化執行器與自適應恢復機制,支援手機遠端控制與即時螢幕串流,實現在筆電上全程離線操作,提升隱私與可控性,同時展示開源方案相較於商業雲端助理的可檢視與安全優勢與開放性。
深度分析
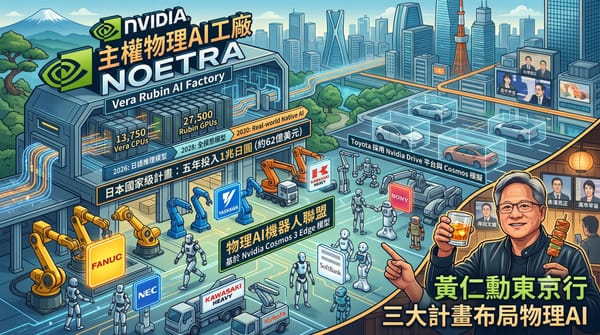
Nvidia執行長黃仁勳訪日促成三大合作:Noetra國家AI工廠將於2028年啟用,日本政府投入1兆日圓發展國產物理AI。Fanuc、Toyota等大廠採用Cosmos 3 Edge模型,目標2040年導入千萬台AI機器人,搶佔全球三成市場。

端側推理
2026 年,隨著小型語言模型與高效能邊緣晶片的成熟,企業開始將推理搬回本地,擺脫雲端 API 的高延遲與高成本。本文從技術突破、混合架構到未來 Physical AI 趨勢,提供完整的實務藍圖與觀測性設計建議。

推理模型降價
2026 年推理模型 API 價格大幅下降,催化 AI 從聊天機器人邁向自主代理時代。本文探討成本雪崩的驅動因素、自主邏輯鏈如何取代單次生成、具體應用案例(Button 硬體、Pinterest 嵌入優化、Perplexity 混合編排),以及工程可靠自動化的關鍵挑戰。最後展望 AI 作為預設基礎設施的未來。
深度分析
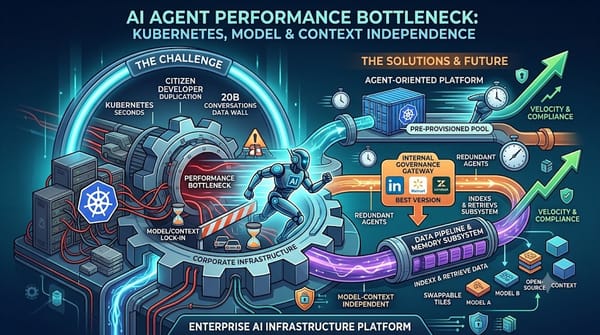
LinkedIn、Walmart、Zendesk三大企業發現AI代理效能受限於傳統基礎建設,透過預配置容器、內部治理閘道與強化資料管線等方式提升速度,同時推動模型與上下文獨立化,預示企業未來將更倚賴自建平台而非僅依賴雲端供應商,並加速跨部門協作與安全合規。
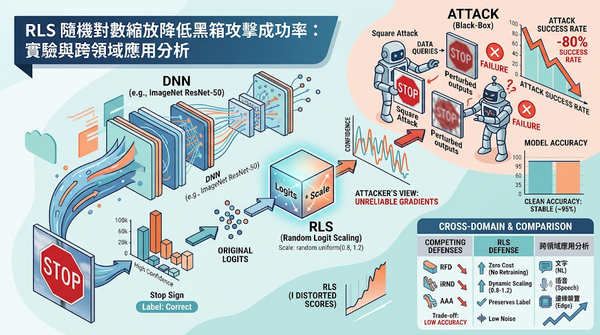
深度分析
隨機對數縮放(RLS)作為後處理防禦,透過隨機放大模型 logits 產生偽造分數,擾亂黑箱分數式攻擊。實驗在 CIFAR‑10 與 ImageNet 表現,將攻擊成功率最高降低 80%,且幾乎不影響準確率。較以往的隨機噪聲防禦,RLS 同時提升了對 Square、Bandit 攻擊的抵抗。
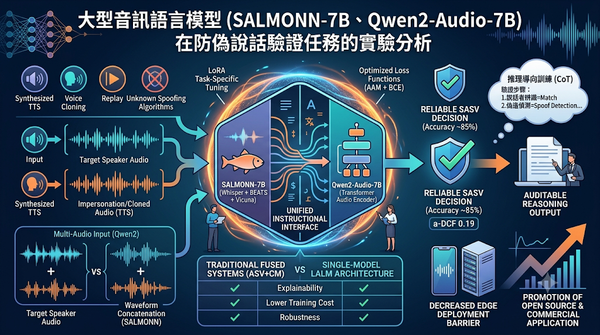
深度分析
近年文字轉語音技術成熟,威脅語音驗證安全。研究將大型音訊語言模型應用於防偽說話驗證,透過 LoRA 微調、損失函數調整與推理監督,取得與傳統融合系統相當的準確度,同時比較了多音訊輸入與串接方式的效能差異,並預測此技術將降低邊緣裝置部署門檻,促進開源生態與商業化應用。

深度分析
針對約束求解器開發的高門檻,CoreForge 嘗試利用 LLM 直接將 MaxSAT 研究論文轉譯為 C++ 程式碼。該流程透過 ChatGPT 規劃、Codex 實作並結合反覆審核與基準測試,成功建構出包含 OLL 演算法與創新前瞻機制的求解器。結果顯示 LLM 能有效處理高層演算法轉譯,雖效能未達頂尖水平但能確保正確性,證明 AI 輔助理論實作的可行性。
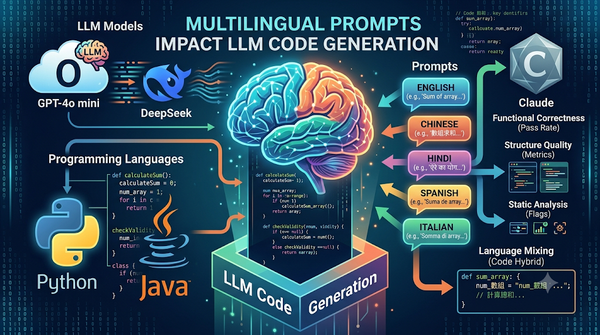
速報
研究探討不同語言提示對大型語言模型程式碼生成的影響,將 460 個 Python 與 Java 任務的英文提示翻譯成四種語言,測試 GPT‑4o mini、DeepSeek、Claude。結果顯示英文提示未必最佳,語言影響視程式語言與模型而定,生成程式碼常混用英語與提示語言。
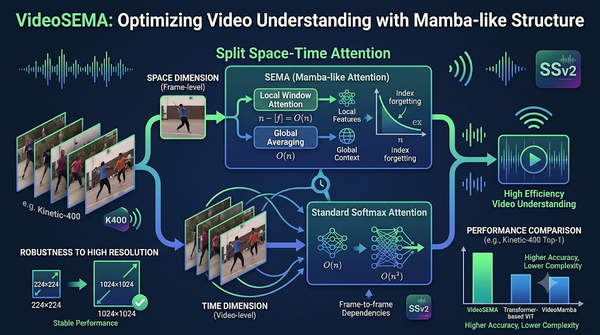
深度分析
針對視訊理解中運算成本過高的挑戰,研究團隊提出 VideoSEMA 模型。該技術採用空間-時間分離注意力框架,在空間端導入類 Mamba 的 SEMA 模組以降低複雜度,時間端則維持標準注意力機制。實驗顯示,VideoSEMA 在 K400 與 SSv2 數據集上的準確率優於同規模的 Transformer 與 Mamba 模型,且能更穩定地處理高解析度視訊輸入。