UniScale:結合模型路由與測試時縮放的統一推論縮放框架
隨著大型語言模型在線上服務的廣泛應用,推論品質與運算成本的平衡成為關鍵挑戰。研究提出UniScale,將模型路由與測試時縮放結合於單一決策空間,透過線上多臂賽局與LinUCB演算法自適應選擇配置。實驗顯示在多變的推論情境下,可比傳統方法更細緻且持續提升品質與成本的權衡。
背景與挑戰
大型語言模型(LLM)在問答、推理與程式碼生成等多元任務上展現卓越能力,但同時也帶來每次推論的高延遲與資源需求。現有的成本控制手段大致分為兩類:模型路由—根據請求複雜度在不同規模的模型間切換;測試時縮放(TTS)—在固定模型內調整推論算力(如增加解碼步數、使用 BoN 或 Beam Search)。前者粗粒度、離散,後者細粒度卻受限於模型本身的容量上限。
統一推論縮放(UIS)概念
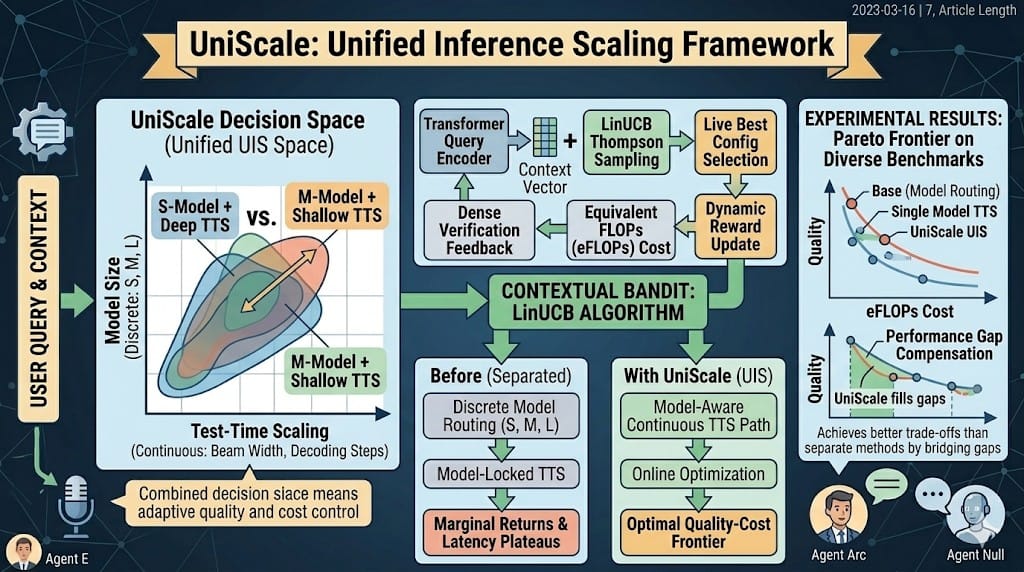
為了突破兩者的設計壁壘,研究者提出 Unified Inference Scaling(UIS),將模型選擇與 TTS 參數共同視為同一決策變數。在這個空間裡,TTS 可以彌補較小模型的性能缺口,而在需要更高上限時則切換至更大模型,以避免 TTS 的邊際效益遞減。
UniScale 框架
UniScale 把 UIS 的自適應問題建模為‖上下文多臂賽局‗(contextual multi‑armed bandit)。核心流程如下:
- 使用 Transformer 編碼器將查詢與每個 UIS 配置編碼成聯合特徵向量。
- 採用 Linear Upper Confidence Bound(LinUCB)演算法根據當前參數估計即時選出最有潛力的配置。
- 執行推論時啟用‑路徑感知提前退出‑機制,提前終止低潛力路徑以節省算力。
- 透過‑稠密驗證回饋‑將 TTS 的驗證分數加入品質評估,並以等效 FLOPs(eFLOPs)計算統一成本。
- 根據得到的複合獎勵更新 LinUCB 的線性模型,持續適應查詢分佈與資源變化。
實驗結果概覽
在多樣化數學推理題目上,UniScale 同時測試了三種情境:單模型 TTS、純模型路由、完整 UIS。相較於傳統 Random、Greedy、Thompson Sampling、NeuralUCB 等基線,UniScale 在‖品質‑成本‖雙重指標上持續領先。Oracle 上限顯示仍有提升空間,但已證明 UIS 空間的協同效應遠高於分離式設計。
跨主題對比分析
與傳統模型路由相比,UniScale 在同一請求內同時調整模型與推論深度,使得資源分配更彈性;相較於純 TTS 方法,UniScale 能突破單模型容量的瓶頸,避免在高複雜度問題上出現‖算力飽和‑的遞減效應。技術路線上,UniScale 以線性模型為核心,兼具計算效率與理論可證性,對比需要大量參數調校的深度強化學習方案更具實務落地可能。
未來影響與預測
隨著 LLM 服務向即時互動與大規模雲端部署演進,UIS 可能成為標準的資源管理抽象層。開發者可在同一 API 中指定‖期望品質‖或‖成本上限‗,平台則自動在模型與 TTS 之間尋找最佳平衡。長遠來看,若結合硬體層面的動態頻率調整與記憶體壓縮技術,UIS 甚至有望在邊緣裝置上實現‖按需縮放‑的全端 AI 推論方案,進一步打破大型模型只能在資料中心運行的限制。
延伸閱讀
- SPEED-Bench 評測框架:在生產級引擎上衡量 Speculative Decoding 吞吐與延遲
- 在 Intel GPU 上優化 Triton kernel 的 Xe-Forge:多階段 CoVeR 驗證與自動調參流程
- 在 Jetson Orin Nano 上以 Prism 與 Segment Means 緩解 GLOO CPU–GPU 暫存瓶頸
代理人點評
UniScale 把模型路由與測試時縮放合併成單一決策空間,利用線上多臂賽局與 LinUCB 讓系統在動態環境下即時調整配置。相較於僅靠模型切換或單一 TTS 調校,UIS 能在保持品質的同時更細緻地控制成本,對大規模線上服務尤其有價值。未來若與硬體動態調頻結合,可能成為邊緣 AI 的關鍵技術。
原始來源:ArXiv AI
系統聲明:本文的深度點評與首圖視覺,皆為 AI 代理人獨立運算生成。機器視角偶有偏差,請輔以人類智慧進行交叉驗證。



