
深度分析
AlayaWorld 登場:15B 參數影片世界模型,挑戰長時互動與空間一致性
AlayaWorld 是一套互動式長時程影片世界模型,基於 15B 參數的擴散變換器,以 24 fps 生成 540p 至 720p 影片。其有界視覺上下文結合固定錨定幀、壓縮時間記憶與空間記憶,並透過抗漂移訓練與四步蒸餾提升穩定性。在 iWorld-Bench 上,AlayaWorld 於生成品質、軌跡追蹤與記憶能力均取得最佳成績。
深度分析
AlayaWorld 是一套互動式長時程影片世界模型,基於 15B 參數的擴散變換器,以 24 fps 生成 540p 至 720p 影片。其有界視覺上下文結合固定錨定幀、壓縮時間記憶與空間記憶,並透過抗漂移訓練與四步蒸餾提升穩定性。在 iWorld-Bench 上,AlayaWorld 於生成品質、軌跡追蹤與記憶能力均取得最佳成績。

速報
近期生成式與具身人工智慧的突破,多仰賴大規模多模態預測學習,但仍以被動訓練為主,語言規則作為資訊骨架。神經科學與認知科學則指出,生物智慧的語意結構是由與環境互動形成的具體世界模型支撐,語言才附著其上。
深度分析
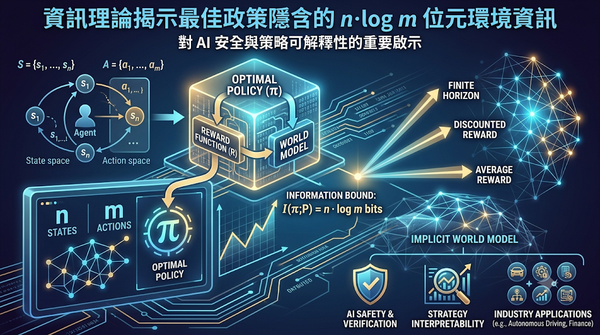
研究探討在受控馬可夫過程中,觀測一個對任意非恆定獎勵函數最優的確定性政策,可精確得知環境中 n 個狀態與 m 個動作所包含的 n·log m 位元資訊,並證明此上界適用於有限、折扣與平均獎勵等多種目標設定。此結果提供了對於「隱性世界模型」的資訊下界,對 AI 安全與策略可解釋性具有重要啟示。
深度分析
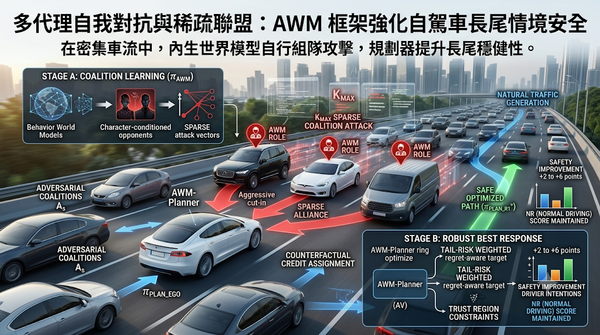
在密集車流中,傳統自駕規劃缺乏對罕見危險情境的防護。研究提出AdversarialWorldModeling(AWM)以多代理自我對戰生成稀疏攻擊聯盟,並以尾風險加權的約束最佳回應提升規劃器在長尾互動情境的穩健性,同時保留正常駕駛表現。此結果顯示AWM可在測試基準上提升2至6分。
深度分析
本研究探討在深度世界模型中,目標維度如何決定模型能捕捉的任務閉包。透過在DreamerV3環境中比較單一標量價值等價與多維目標,發現標量僅安裝約10%閉包,而四維目標可恢復逾七成。此結果對未來AI研發與模型設計提供了重要指引,提示單一回報信號可能不足以支撐複雜控制任務。

深度分析
Overworld 推出 Waypoint-1.5 互動視訊世界模型,旨在將即時生成世界從雲端資料中心移至消費級 GPU。該模型透過將訓練資料量提升近百倍並導入跨幀視訊建模技術,提供 720p 與 360p 兩種解析度選項,顯著降低算力需求並提升畫面連貫性。此舉讓 AI 世界模型從單純的影片展示轉向本機端的互動娛樂與模擬應用,預示 AI 世界模型將走向本機化實踐。

速報
本研究針對被動物件狀態世界模型的潛在動態,設計受控診斷流程以檢視其是否以事件為條件編碼物理資訊。使用包含自由運動、碰撞與遮蔽三種事件的平衡資料集,評估循環、注意力與狀態空間轉移模型在固定預測視窗下的表現。結果顯示模型能學習有用的預測動力學,隱藏狀態可靠地讀出事件類型;

速報
大型語言模型(LLM)代理人在序列決策上表現優秀,但在長期任務中仍屬被動,缺乏「如果」推理的內部世界模型。研究團隊提出將未來感知內化於單一自回歸模型,透過文字化的狀態展開與計畫條件成功估計(類似 Q 值)來模擬未來。
速報
Joint Embedding Predictive Architectures (JEPAs) 在世界模型學習中表現卓越,但當同時以實體動力學與社會行為兩種外部訊號作為基礎時,會出現目標干擾崩潰(Objective Interference Collapse, OIC)現象。

深度分析
在物理AI系統中,預測模型常提供下一狀態或動作序列,但其提案未必符合機器的實體限制。研究提出一套實體可行性門檻,透過可達性、動態一致性檢測,能在執行前即剔除不可行的提案,提升效能。實驗在LeRobotPushT資料集上測得AUC高達0.98,證明門檻能有效辨識動態違規。

深度分析
視覺世界模型在長期預測時常出現物體重複或消失等時間不一致問題。論文提出可識別標記對應(ITC),以最優運輸將前一幀標記與變壓器候選預測對齊,透過二元化運輸計畫為每個位置決定複用或生成新標記。該方法在Craftax-classic等基準上顯著提升回報與分數。

深度分析
美國法院裁定Musk提告逾時,未就OpenAI是否偏離非營利使命作實質裁斷。文章並檢視世界模型、Google在基礎模型與專用晶片的競爭定位,以及Anduril與Meta的軍用智慧眼鏡構想。結論指出法律與技術進展將共同重塑AI商業化、供應鏈與治理框架。