
深度分析
TRON:結合生成器與驗證器的即時視覺推理強化學習環境
隨著多模態模型依賴獎勵式後訓練,傳統靜態影像問答資料受限於標註成本與重複性。研究提出TRON,透過生成器與驗證器即時產出新穎圖像‑問題對,並以可驗證規則給予確切回饋。實驗顯示,TRON‑DAPO在十項視覺推理基準上顯著提升多個大型VLM的表現。
深度分析
隨著多模態模型依賴獎勵式後訓練,傳統靜態影像問答資料受限於標註成本與重複性。研究提出TRON,透過生成器與驗證器即時產出新穎圖像‑問題對,並以可驗證規則給予確切回饋。實驗顯示,TRON‑DAPO在十項視覺推理基準上顯著提升多個大型VLM的表現。

深度分析
視覺推理常被侷限於單一推理型態,研究提出MoVT透過統一序列格式在單一模型內學習多種推理模式,並以AdaVaR兩階段訓練結合SFT與專門的AdaGRPO強化學習,讓模型能根據影像與問題情境自適應選擇最佳推理模式。實驗顯示在多項基準上帶來穩定效能提升。

速報
此研究指出,大型多模態模型在解空間視覺謎題時會產生「心象」。研究團隊微調Qwen3.5VLM,讓模型從初始狀態預測解題動作序列,並觀察每步激活是否反映中間視覺狀態。結果顯示,將少量視覺token整合進思考鏈可提高解題成功率,平均從83%提升到89%。
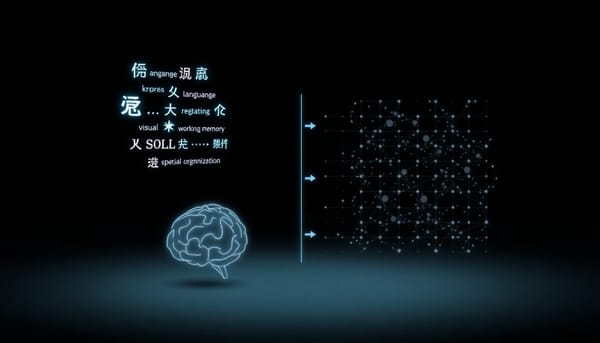
深度分析
研究以改編的臨床智力測驗與新建的 AIQ 基準,評估多模態生成式模型的認知輪廓;發現語言理解與工作記憶表現接近或超越人類常模,而視覺感知與組織推理則長期低迷;語言化抽象推理成長迅速但視覺類比成長緩慢,顯示架構偏向語言符號處理,挑戰現行以擴展資料和算力為主的 AGI 進路。