
深度分析
RepTran:基於差分演化的 Transformer FFN 搜尋式修復方法
隨著Transformer成為AI應用核心,其錯誤會影響系統可靠性。研究提出RepTran,結合變異性神經元分數與雙向分數,透過差分演化搜尋修正FFN權重。實驗顯示平均修復率達74.7%,顯著優於現有方法。在CIFAR-100與Tiny-ImageNet測試中,最高95.2%修復率,耗時約476秒。
深度分析
隨著Transformer成為AI應用核心,其錯誤會影響系統可靠性。研究提出RepTran,結合變異性神經元分數與雙向分數,透過差分演化搜尋修正FFN權重。實驗顯示平均修復率達74.7%,顯著優於現有方法。在CIFAR-100與Tiny-ImageNet測試中,最高95.2%修復率,耗時約476秒。

深度分析
研究以超過15億張影像文字配對與10億段影片標籤,建構統一視覺模型Xray‑Visual。模型採三階段訓練:自監督MAE、半監督標籤分類與CLIP對比學習,並以EViT令token效率提升。實驗顯示在ImageNet、Kinetics及MS‑COCO上均創新紀錄,同時在域轉移與對抗擾動下保持韌性。

深度分析
研究指出,視覺Transformer在測試時常以注意力分數過高的影像標記作為防禦依據。研究者提出獨立優化的對抗誘餌貼片,將注意力引向無害目標區域,同時保留原始對抗貼片的攻擊效果。實驗顯示,誘餌能有效降低防禦遮罩與真實攻擊區的重疊,攻擊成功率仍保持相當水平。
深度分析
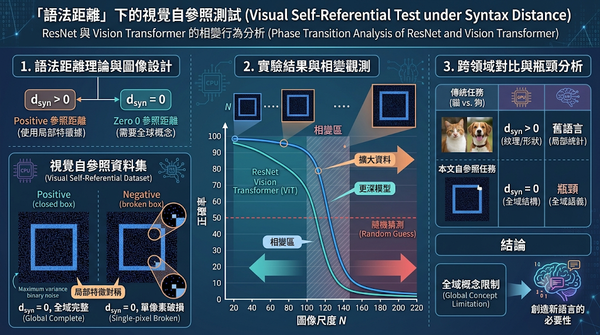
本研究探討視覺模型在缺乏局部特徵線索時的辨識能力,透過語法距離概念構建閉合方框與單像素破損方框的自參照圖像。實驗顯示,隨著圖像尺度超過臨界點,ResNet與ViT的正確率跌至隨機猜測,僅靠擴大資料或模型規模無法突破此上限。此結果揭示現有架構在全域概念任務上的結構性限制。

深度分析
Vision Transformer 因自注意力計算量大而難以部署,研究提出 RAPID 以層級感知的冗餘剪枝與重要性合併減少 token。淺層使用冗餘相似度剪除重複局部特徵,深層則保留關鍵 CLS 權重的 token 並合併相似次要 token。實驗顯示在極端壓縮下,RAPID 的準確度比 ToMe 高出 4.29%。

深度分析
研究針對測試時適應的領域變化,提出DOME以零樣本方式顯式編碼每筆影像的領域變數,結合視覺語言預訓練與稀疏動量庫監督,使即便簡單的熵最小化也能在ImageNet-C、R、Sketch上達到最新水平。實驗顯示,加入DOME後,主流TTA方法提升約1.5%,且計算開銷僅增少量。

深度分析
隨著視覺Transformer在自駕與醫療影像等安全關鍵領域的應用增加,研究提出SENTRY統計軟錯注入框架,利用有限抽樣在千樣本下提供99%信心水準與1%誤差,將實驗成本降低一萬倍。結果顯示僅3%位元翻轉會致災難性準確率下降,且主要集中於LayerNorm層與FP32指數,為未來硬體加固指明方向。

深度分析
隨著視覺Transformer在邊緣裝置的部署受限,研究提出MaskAQ以遮罩注意力對齊方式在無資料情況下生成高品質樣本,聚焦稀疏資訊區域,提升量化模型的校準效果,實驗顯示在ImageNet上3位元量化可提升3.1%準確率。同時,此方法在目標檢測與語意分割等下游任務亦展現穩定優勢。

深度分析
隨著模型規模不斷膨脹,剪枝成為降低記憶體與運算成本的關鍵技術。研究提出STARFISH方法,利用少量未標記影像校正集,使剪枝後的網路內部表示與原始模型對齊,從而恢復精度。實驗顯示,在75%權重被剪除的情況下,STARFISH只需0.4%訓練影像即可恢復原始模型82%的準確率,遠超其他方法。
深度分析
本研究把人類凝視密度圖用作微調視覺轉換器的自注意力權重,並以洗牌控制驗證信號語義性。微調後模型在五項顯著性度量上與人類注視更接近,且自發出現三類人類注意偏好:動物優先、小物體偏好與注意更集中。關鍵發現是,這類對齊在原始、受損與分布外影像上未造成分類性能下降。

深度分析
本研究針對視覺轉換器的自注意力計算瓶頸,提出全矩陣運算的 MaMe 令牌合併與 MaRe 復原技術,於 ViT‑B 提升兩倍吞吐僅降 2% 準確度,並在多項任務展現加速與品質提升。

深度分析
研究聚焦於 Vision Transformer 內部激活的可解釋性,提出跨層轉碼器作為稀疏、深度感知的代理模型,利用編碼‑解碼重建激活並分解最終表徵。實驗證明 CLT 在多資料集上保持高重建忠實度,甚至提升零樣本分類準確率,且層貢獻分數顯示關鍵層對表徵影響顯著。