深度分析
視覺語言模型的問題先行悖論:提示回呼如何提升問答準確性
在視覺語言模型(VLM)中,直覺上認為先給問題能引導模型注意影像內容,然而實驗發現「問題先行」的提示方式在多項基準測試上表現最差,形成所謂的問題先行悖論。研究者透過 logit‑lens 與注意力探測證實,先問問題確實能驅動影像特徵向問題相關概念靠攏,但因問題被長長的影像序列隔離,答案產生階段幾乎不會讀取到問題,導致錯誤答案。
深度分析
在視覺語言模型(VLM)中,直覺上認為先給問題能引導模型注意影像內容,然而實驗發現「問題先行」的提示方式在多項基準測試上表現最差,形成所謂的問題先行悖論。研究者透過 logit‑lens 與注意力探測證實,先問問題確實能驅動影像特徵向問題相關概念靠攏,但因問題被長長的影像序列隔離,答案產生階段幾乎不會讀取到問題,導致錯誤答案。

深度分析
隨著機器人學習需要大量物理互動資料,傳統人力收集成本高昂。研究提出 RADAR 系統,利用少量 3D 示範結合視覺語言模型與圖神經網路自動產生任務、執行並以 VQA 評估成功,最後以 FSM 完成環境自動重置。實驗顯示在模擬與實機上可達 90% 成功率,顯著提升資料取得效率。

深度分析
在視覺語言模型的社會認知測試中,研究團隊以 FlipSet 這套 L2 視覺視角推理基準,對 103 種公開模型進行零樣本評估。結果顯示,超過七成的回答是自我中心的相機視角,整體正確率僅 9%,遠低於 25% 的機會水平,說明模型在將他人視角與空間旋轉結合時存在根本缺失。此問題若不解決,將限制多模態 AI 在真實互動情境中的應用。

深度分析
研究團隊探討測試時擴展技術在小規模視覺語言模型上的適用性,並在多國語言視覺選擇題基準 EXAMS-V 上進行測試。透過對比 Qwen 系列模型,研究發現效能提升關鍵在於基礎模型能力、正確的解析格式與充足的解碼代幣預算,而非複雜的搜尋機制。最終配置在 ImageCLEF 2026 測試集達到 84.1% 準確率,位居榜首。

深度分析
視覺語言模型轉為視覺語言動作模型的挑戰在於輸出分布不匹配,CLAP透過在動作代幣前加入自然語言描述,使預訓練語意保留,同時僅需單輪微調即可在LIBERO測試中達到90.8%成功率,顯示此簡潔流程提升效能且易於分析。預期此方法將加速多模態機器人開發,降低門檻。

深度分析
FalconPerception以0.6億參數的早期融合Transformer取代傳統視覺管線,透過混合注意力遮罩同時處理影像與文字,於SA‑Co基準取得68.0Macro‑F1,並推出PBench診斷測試與0.3億參數的FalconOCR,顯示單模型可同時支援分割與文件辨識。
深度分析
隨著視覺語言模型被廣泛用於流程圖圖像轉程式碼,缺少參考碼使品質監控困難。研究提出以OCR產生文字作為參考的Recall_OCR,並以視覺蕴涵驗證生成內容的Precision_VE,合成F1_OCR-VE作為品質指標。實驗在FlowVQA上驗證,與真實指標相關係數分別達0.97、0.91、0.94。
深度分析
長尾實例分割受限於資料稀缺,研究提出結合 T2I 生成與情境感知 I2I 編輯的混合框架,透過教師‑學生過濾與 VRAIN 指令式稀有類別插入,提高標籤可信度與影像真實感。實驗在 LVIS 上整體 AP 提升 4 點,稀有類別更增 9.5 點,顯示此方法在提升模型表現與擴展性方面具備顯著潛力。

速報
隨著視覺語言模型(VLM)、對話模型(DM)、大型語言模型(LLM)與音訊生成模型(AFM)在各領域的廣泛應用,這些多模態基礎模型往往會不自覺地保留訓練資料中的敏感、受版權保護、偏見或不安全的跨模態關聯。因知識分布於共享表徵,刪除請求或政策更新後的重新訓練成本高昂,且精準遺忘困難。

深度分析
本研究提出ZendoWorld互動基準,結合視覺感知、歸納推理與實驗設計,讓AI代理在多回合中推測隱藏規則並主動生成測試場景。實驗顯示,僅靠標籤預測的高準確度無法保證規則恢復,VLM代理往往提出資訊量低的實驗,難以降低假設不確定性。此基準為評估與提升主動視覺概念學習提供方向。
深度分析
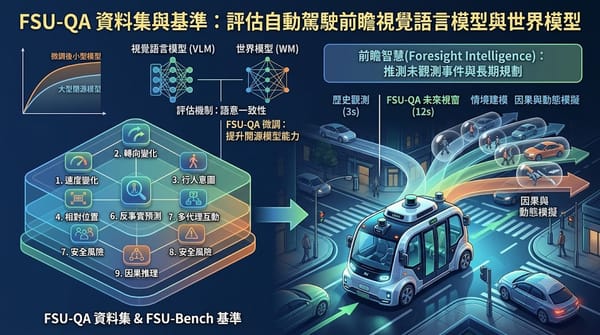
研究背景:視覺語言模型多聚焦於即時感知,忽略未來推測。核心做法:提出FSU‑QA資料集與FSU‑Bench基準,設計九項自駕前瞻任務,並以VLM評估World Model生成之未來影像之語意一致性。主要結果:即使是小型模型經FSU‑QA微調,也能超越多數大型閉源模型,顯示該基準有效提升前瞻推理能力。

深度分析
對話式影像編輯需保留暫時被遮蔽卻未改變的內容。研究推出OCCUR-Bench測試集,並提出無需訓練的ReSpec框架,透過歷史參考影像與修復指令顯化隱含保存意圖。實驗顯示在恢復真實度與時間一致性上顯著優於既有編輯模型。此技術有望提升長對話編輯的可靠性,並推動開發者在影像AI工具中加入歷史記憶機制。