
深度分析
「ExtremeWhenBench」揭示長影片時序搜尋瓶頸:檢索‑定位混合模型提升 Video‑LLM 效能
研究指出,對於超過半小時的長影片,語言模型的主要瓶頸在於搜尋而非辨識。作者推出ExtremeWhenBench基準,發現傳統影片‑LLM在長片上表現崩潰,框架式的檢索再定位方法可提升約6.7倍的mIoU,此結果暗示未來影片搜尋與內容分析需重新設計,結合檢索與生成或成主流方向。同時,研究也指出檢索階段的效能提升可直接降低影片‑LLM的運算成本。
深度分析
研究指出,對於超過半小時的長影片,語言模型的主要瓶頸在於搜尋而非辨識。作者推出ExtremeWhenBench基準,發現傳統影片‑LLM在長片上表現崩潰,框架式的檢索再定位方法可提升約6.7倍的mIoU,此結果暗示未來影片搜尋與內容分析需重新設計,結合檢索與生成或成主流方向。同時,研究也指出檢索階段的效能提升可直接降低影片‑LLM的運算成本。
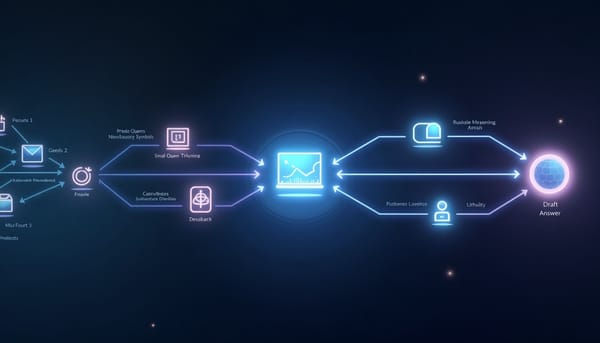
深度分析
隨著Video‑LLM在長影片推理上的突破,研究提出CoVER框架,結合查詢擴充取得多元視覺證據與答案線索驅動的視覺回饋驗證,形成閉環推理流程。實驗顯示在MLVU、LVBench等基準上提升3至5個百分點,顯示完整證據取得與答案驗證對長影片理解的關鍵價值。

深度分析
線上影片大型語言模型在即時串流時常因回應產生暫停,導致視訊與語音不同步。研究提出LyraV結合框架式轉換控制器與串流標記節奏器,以每框僅產生少量詞彙,實現98%同步率與3.89FPS的即時表現,此技術亦為未來AR眼鏡與機器人助理提供持續感知與即時敘事的基礎。