速報
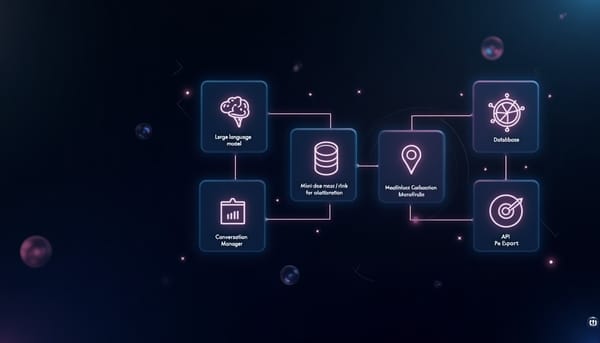
Langflow:以視覺化串接大型語言模型與多代理工作流程
在開源生態中,Langflow以視覺化編輯器為核心,結合可存取原始碼的自定義能力,支援主要大型語言模型與向量資料庫,提供互動式測試與多代理協作,並能匯出JSON、部署為API或MCP伺服器,搭配觀測方案協助監控,讓開發者更快整合AI工作流程到應用中。
速報
在開源生態中,Langflow以視覺化編輯器為核心,結合可存取原始碼的自定義能力,支援主要大型語言模型與向量資料庫,提供互動式測試與多代理協作,並能匯出JSON、部署為API或MCP伺服器,搭配觀測方案協助監控,讓開發者更快整合AI工作流程到應用中。

Model Context Protocol
Anthropic 限制 Claude 後,開源社群推出新工具 Build‑Agentic‑AI‑and‑Gen‑AI‑Agents‑with‑MCP,透過 Model Context Protocol 串接 LangChain、CrewAI,提供跨平台安裝與向量資料庫支援,協助開發者快速建置 AI 代理工作流。

深度分析
VBPulse調查指出2026年第一季企業對混合檢索的採用意願在一季內由10.3%增至33.3%。企業從單一向量檢索轉向結合稠密向量、關鍵字搜尋與重排的混合架構,以求在代理化工作負載下取得檢索精準與運行可靠性的平衡。檢索層成為企業能否在大規模代理應用維持可信度與合規性的關鍵之一。

AnythingLLM
此篇介紹開源專案AnythingLLM,聚焦本地化與隱私優先的AI工作流程。專案結合檢索增強生成、向量資料庫與本地LLM,提供文件聊天、AI代理與多使用者管理。該平台聲稱降低部署門檻,對追求離線推理與資料可控的團隊具實務意義。同時社群活動活躍、文件與測試案例豐富,便於評估與導入。

RAG
All‑in‑RAG 是一個以 Python 為主的開源教學專案,聚焦檢索增強生成(RAG)技術,提供從理論到實作的系統化學習路徑與實例。專案整合 LangChain、llama‑index、向量資料庫等常見工具,涵蓋 embedding、多模態、知識圖譜等主題,並提供線上閱讀與範例程式。

深度分析
面對對話式大模型缺乏持久記憶,研究提出LyzrCognis:以雙儲存層(OpenSearchBM25+向量檢索)與RRF融合,寫入時採語境感知抽取決定新增或更新,加入時間加權與BGE-2重排以強化時序查詢與版本回溯。實驗於LoCoMo與LongMemEval顯著領先。

Claude Code
claude-mem 是一個針對 Claude Code 的開源記憶壓縮系統,能自動擷取開發會話內容、以模型壓縮並持久化儲存,於未來工作階段回填相關上下文。專案以 TypeScript 開發、支援多種記憶後端與嵌入向量,README 顯示多語系說明與相容性資訊,並在社群獲得高度關注。

AI 代理
該GitHub倉庫彙整可執行的100多個AI代理與RAG範本,原始檔案以Python為主,列出代理、語音代理與檢索增強流程的樣板,並標示可配合的多家大型語言模型;對開發者而言,資源能降低上手門檻並加速原型驗證與部署。

深度分析
隨著 AI 代理需求提升,本文介紹 Mem0 結合 OpenAI 與 ChromaDB 的長期記憶架構。透過自動抽取、語意搜尋與 CRUD 管理,實作使用者層級的持久化記憶,並示範多使用者資料隔離與自訂設定。結果顯示,記憶增強可使對話保持上下文連貫,提升個人化回應與系統可擴展性。(原文未詳述)
檢索增強生成
GitHub 新發現 RAG_Techniques 專案提供多項檢索增強生成技術教學,涵蓋 LangChain、LlamaIndex 與向量資料庫整合。結合 UltraRAG、VimRAG 與 Databricks 多步驟代理人等最新研究,提升多模態與混合查詢效能。此專案為台灣 AI 開發者提供可落地的實作範例與產業應用洞見。

UltraRAG 3.0
UltraRAG 3.0於2026年1月正式發布,提供低程式碼的多模態RAG框架。核心採用可視化推理與AgentCPM-Report模型,支援文字、影像與向量檢索。此框架降低開發門檻,預期加速台灣企業的生成式AI應用部署。

深度分析
隨著機密文件外洩風險升高,研究提出檢索增強分類(RAC)作為低洩漏的辨識方案。RAC 結合外部向量庫與相似度匹配,在平衡與不平衡資料上均達 96% 正確率,F1 可至 94%。相較於需重新訓練的監督式微調,RAC 可即時重新索引新文件,降低參數洩漏並提升治理彈性,對企業合規部署具實務價值。