
深度分析
「光譜感受度定理」揭示 Whisper 系列模型的 ASR 幻覺機制
研究指出,隨著 Whisper 系列模型規模放大,幻覺現象會由訊號散佈轉為吸引子動態。透過光譜感受度定理與光譜傳播不穩定框架,分析跨注意力與自注意力的特徵譜變化。結果顯示,小型模型出現結構解體,大型模型則進入壓縮吸引子狀態,對未來語音辨識安全性提出警示。
深度分析
研究指出,隨著 Whisper 系列模型規模放大,幻覺現象會由訊號散佈轉為吸引子動態。透過光譜感受度定理與光譜傳播不穩定框架,分析跨注意力與自注意力的特徵譜變化。結果顯示,小型模型出現結構解體,大型模型則進入壓縮吸引子狀態,對未來語音辨識安全性提出警示。

速報
研究者將旋轉位置編碼(RoPE)應用於圖形資料,提出 Wave‑Induced Rotary Encodings(WIRE)透過圖拉普拉斯譜旋轉 token,將結構資訊注入注意力。實驗顯示在合成與真實圖形任務上皆有顯著提升,且在格點上還原為標準 RoPE,漸近與圖形有效阻抗相關,兼容線性注意力。
深度分析
研究針對混合式語言模型與傳統transformer在不同類型token上的預測表現進行比較。結果顯示混合模型在實詞與代名詞指代上優勢明顯,但在重複文字的抄寫上與transformer差距縮小。此發現提示未來模型設計可針對不同token特性做精細化優化。

深度分析
多任務微調需精準權重分配,研究提出利用貝葉斯模型合併快速預覽不同權重組合,透過參數平均與更彈性後驗分布提升預測品質,實驗在視覺與語言Transformer上證明可選出更佳權重,提升最終微調效能。此方法亦可擴展至其他大型模型,預計將加速多任務學習的商業化部署與研究迭代。

深度分析
ZONOS2 8B以MoE骨幹擴展至8億活躍參數,訓練資料從20萬小時增至超過600萬小時,支援多語言與零樣本語音克隆。新評測ZTTS1‑Eval包含9種朗讀語言與17種自然對話語言,全面衡量自然度、說話者相似度與韻律多樣性。實驗顯示ZONOS2在自然度與克隆相似度上與最先進系統競爭。
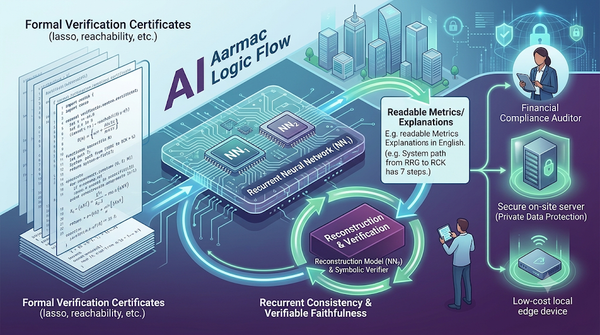
深度分析
本研究針對形式驗證產出的證書,提出循環一致的指標生成神經網路,結合指標生成與逆向重建與符號驗證器,確保解釋忠實且流暢。實驗在金融合規領域420份證書上達90%循環驗證正確率,遠超多模型LLM基線。相較於傳統模板或通用大語言模型,此模型在保護資料隱私、降低推論成本上具優勢,預期將推動金融與安全領域本地化 AI 部署。
深度分析
隨著深度學習分支出卷積、Transformer與循環網路,研究提出可學習的積分變換ITNet,將位置與特徵共同建模,實驗在ImageNet、GLUE與3D點雲等多任務上與專屬模型持平或超越。其核心學習式核同時考慮內容與位置,透過平鋪式融合與低秩分解提升運算效率。
深度分析
研究背景:深層解碼器的殘差聚合僅用固定權重。提出WAVv1,於每個區塊加入注意力與MLP差異、前後半部零和細節基底,並以深度路由。實驗在TinyStories與Text8上顯示,12層較差,24層持平,48層驗證損失最佳,優於BlockAttnRes、ReZero與LayerScale。

速報
NVIDIA 發布 Cosmos 3 系列全域式多模態世界模型,能同時處理與產生文字、影像、影片、音訊與動作序列,採用混合 Transformer 架構,支援高度彈性的輸入輸出配置。此模型統合了視覺語言、影片生成、世界模擬與行動決策等功能,成為實體 AI 的通用骨幹。

速報
研究者將五種最新的視覺語言模型與 600 名受測者同時放入網路版 Visual-World 實驗,讓他們在觀看六秒短片時,同步判斷下一個詞彙的出現機率,並追蹤眼球移動。結果顯示,加入視覺資訊後,模型與人類在可預測性評分上的相關性提升(平均 Δr = 0.18),且模型參數規模對此影響不大。

深度分析
隨著MoE大語言模型在記憶體需求上受限,研究者提出「專家參照」於相鄰層共享FFN權重,同時保留層級路由與注意力。實驗顯示記憶體使用降低近2倍,且困惑度與下游效能幾乎不受影響。在g=4的層組設定下,專家權重共享達到4倍參數壓縮;若將節省的參數再投入擴充中間層的專家數量,亦可在等參數條件下恢復效能。

深度分析
本研究將深層transformer視為受通信、局部與深度限制的平均場互動系統,提出利用層間功能向量進行自適應推論,並在具層級結構的線性回歸任務中證實,深度與MLP區塊的結合能顯著降低預測誤差功能向量作為上下文的緊湊摘要,使查詢能在單次前向傳播即獲得最佳後驗分布。