
深度分析
解讀Transformer注意力模式,預測AI模型在分布外數據的行為
本研究利用可解釋性工具分析Transformer模型的注意力模式,預測其在未見過數據上的行為。在合成任務中,數百個模型展現不同歸納規則,而階層性注意力模式與OOD階層性歸納規則高度相關,即使該模式非因果必要。此發現為AI模型評估與除錯提供新方向。
深度分析
本研究利用可解釋性工具分析Transformer模型的注意力模式,預測其在未見過數據上的行為。在合成任務中,數百個模型展現不同歸納規則,而階層性注意力模式與OOD階層性歸納規則高度相關,即使該模式非因果必要。此發現為AI模型評估與除錯提供新方向。
深度分析
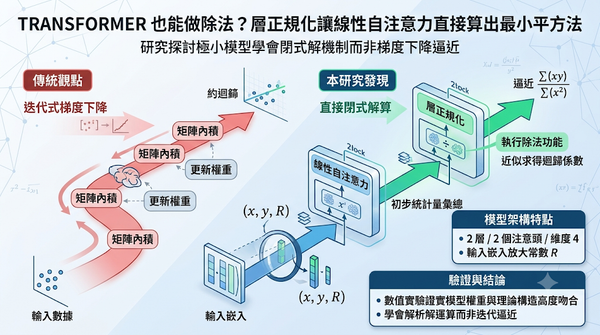
研究探討 Transformer 在上下文學習中,如何利用線性自注意力結合層正規化,直接近似求得線性迴歸的最小平方法,而非傳統的梯度下降迭代。作者構建了一個僅有 2 層、2 個注意頭、維度 4 的小型模型,並在加入 ℓ1 正則化的訓練下,證實模型會學會以層正規化執行除法運算,產生閉式解。

深度分析
隨著語言模型規模持續擴大,研究提出Gate‑ZeroGrowth以零門控方式在持續學習中保留函數。該方法透過零初始化門將新殘差塊加入模型,理論保證舊參數不變且新參數在成長點平坦。實驗顯示在300M→857MTransformer上幾乎零遺忘,優於未使用零門控的基線。

深度分析
隨著Transformer成為AI應用核心,其錯誤會影響系統可靠性。研究提出RepTran,結合變異性神經元分數與雙向分數,透過差分演化搜尋修正FFN權重。實驗顯示平均修復率達74.7%,顯著優於現有方法。在CIFAR-100與Tiny-ImageNet測試中,最高95.2%修復率,耗時約476秒。

深度分析
研究針對 Transformer 中的前饋網路神經元,提出免訓練歸因方法,發現僅需少量前層激活與注意力輸出即可重建神經元激活,且在適度稀疏下模型困惑度不變。實驗覆蓋 GPT‑2 系列與 Qwen2.5 多種規模,顯示約 17%‑19% 神經元具可辨識的專門計算,且稀疏路徑呈次線性增長,為模型壓縮與電路解釋提供新方向。
深度分析
研究聚焦於資料不平衡對抗虛假相關的影響,發現高比例捷徑樣本在容量足夠的模型中會使反捷徑梯度放大,促使注意力電路重組,提升對抗測試準確率。此發現挑戰了傳統上必須平衡資料的做法,並提供了一條利用不平衡提升模型魯棒性的路徑。實驗在多種二元與三元任務上皆驗證,顯示此機制與資料比例偏離隨機基準的程度相關。

深度分析
Allen AI 推出的 DiScoFormer 以 Transformer 同時估算資料分布的密度與分數,訓練使用高斯混合模型生成的樣本。實驗在100維度上顯示密度誤差比最佳KDE低逾37倍、分數誤差減少約6.5倍,且記憶體需求更佳。此技術有望降低高維度分析成本,推動生成模型與科學模擬等領域創新。
深度分析
本研究探討小型 Transformer 如何在合成模數下學習模組整數乘法,這是一種因零因子而非全域可逆的運算。作者提出「單位擴展」概念,認為模型會將輸入空間劃分為局部代數層級(𝒥‑類),在每個層級內仍保留類群結構,允許應用局部傅立葉特徵與局部逆元。

速報
音訊智慧涵蓋理解、推理與生成。研究團隊推出 Audex,採單一解碼器將音訊投射至文字嵌入,並統一處理文字與量化音訊 token,訓練資料逾 470 億 token。實驗顯示 Audex 在語音辨識、翻譯、語音合成等多項音訊任務上創下新紀錄,且保留文字模型的推理與長上下文能力,模型已開源供研究。

深度分析
Allen Institute for AI 推出的 DiScoFormer 以 Transformer 架構,在單次前向傳播即能估算任意資料分布的密度與分數,解決傳統核密度估計在高維度下精度急衰、神經分數模型需重新訓練的兩大痛點。

深度分析
隨機臨床試驗與線上A/B測試需要兼顧推論有效與效率,研究提出以Transformer作為貝葉斯實驗者,透過注意力聚合歷史資料模擬貝葉斯後驗Neyman分配,實驗顯示可自動適應結果平滑度並接近最佳配置,提升ATE估計精度,此方法亦可延伸至政策評估與資安風險測試,提供可解釋且自動化的實驗設計框架。

深度分析
機器學習常需從樣本推估分布的密度與分數。DiScoFormer以Transformer結構結合交叉注意力,同時輸出密度與分數,並利用無標籤一致性損失自適應不同分布。訓練時以高斯混合模型產生無限目標,實驗顯示在百維度上誤差比傳統KDE多倍降低。