深度分析
企業級 AI 代理人評測標準 VAKRA:四大能力、模型表現與未來走向
VAKRA 是 IBM 研發的企業級 AI 代理人基準,提供 8,000+ 本地 API 與跨 62 領域資料庫的多步工作流程測試。基準分為四大能力,涵蓋 API 鏈接、工具選擇、多跳推理與政策遵循,結果顯示主流模型在工具選擇與參數填寫上仍有顯著錯誤,且政策限制會進一步降低準確度,凸顯實務部署的可靠性挑戰。
深度分析
VAKRA 是 IBM 研發的企業級 AI 代理人基準,提供 8,000+ 本地 API 與跨 62 領域資料庫的多步工作流程測試。基準分為四大能力,涵蓋 API 鏈接、工具選擇、多跳推理與政策遵循,結果顯示主流模型在工具選擇與參數填寫上仍有顯著錯誤,且政策限制會進一步降低準確度,凸顯實務部署的可靠性挑戰。

大佬動態
Meta 於 2026 年 7 月公布 Muse Spark 1.1,為首款提供 API 的 Spark 系列模型。官方稱其在代理式工具呼叫與電腦操作上有顯著提升,並在防止 jailbreak、降低幻覺與提升提示注入防禦方面表現更佳。
深度分析
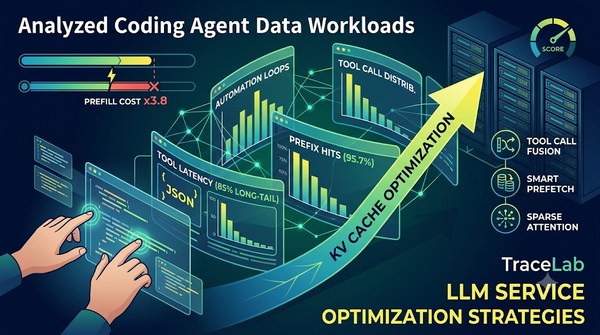
研究針對編碼代理在實務使用中的4,300場會話進行追蹤,發現長自動迴圈、長前綴短輸出、工具呼叫高度分散且快取命中率高。此結果指出降低工具呼叫開銷與改進KV快取管理可提升服務效能。前綴快取全局命中率達95.7%,但在人為間隔較長時仍會失效,導致預填代價提升3.8倍。

深度分析
本篇深度報導探討代理式 AI 系統在執行過程中出現的變異現象,從基礎模型的 token 抽樣機制切入,說明隨機抽樣、決定性解碼與外部環境變化三大變異來源。

深度分析
隨著大型語言模型被用於自動化工具呼叫,通用性仍是挑戰。研究提出 MAVEN 框架以結構化分解、適應性工具編排與中間驗證,並打造 MAVEN‑Bench 壓力測試基準。實驗顯示在不額外訓練下,MAVEN 將 GPT‑OSS‑120b 的正確率從 48% 提升至 71%。

深度分析
隨著多代理人 AI 需求提升,SmolAgents 以程式執行、工具呼叫與動態編排為核心,提供彈性協調機制,實作簡易且支援即時擴充,預計將加速開發者在雲端與邊緣環境部署複雜 AI 工作流。
