深度分析
分層認知的時間序列推理:HiTSR 資料集與 LLaTiSA 多模態模型
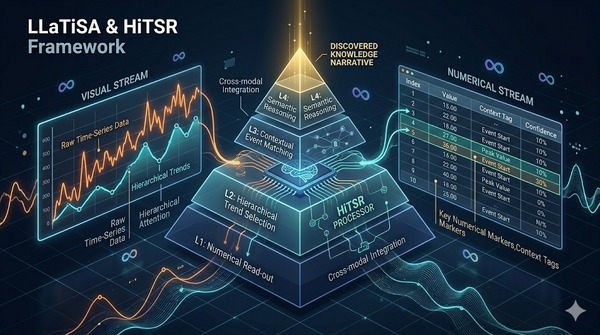
時間序列推理仍是大型語言模型的一大短板。研究團隊提出一套四層難度分類(L1–L4)並發布 HiTSR,一個涵蓋 L1–L3 的高保真資料集(約 83k 筆),所有樣本附可驗證的推理鏈。基於此,提出 LLaTiSA——一個以視覺語意為主、並輔以精準數值索引表格的視覺語言模型,採三階段課程式微調來逐步建立從數值讀取到語意推理的能力。
深度分析
時間序列推理仍是大型語言模型的一大短板。研究團隊提出一套四層難度分類(L1–L4)並發布 HiTSR,一個涵蓋 L1–L3 的高保真資料集(約 83k 筆),所有樣本附可驗證的推理鏈。基於此,提出 LLaTiSA——一個以視覺語意為主、並輔以精準數值索引表格的視覺語言模型,採三階段課程式微調來逐步建立從數值讀取到語意推理的能力。

深度分析
大型語言模型在時間序列任務的真實理解仍未明朗。研究者開發 TimeSeriesExam 與 TimeSeriesExamAgent,前者利用合成序列測試五項推理能力,後者自動從醫療、金融、氣象等實務資料產生基準。實驗證明自動化基準多樣性可比人工設計,然而模型在抽象與領域特化推理上仍受限,顯示時間序列理解仍具挑戰。