速報
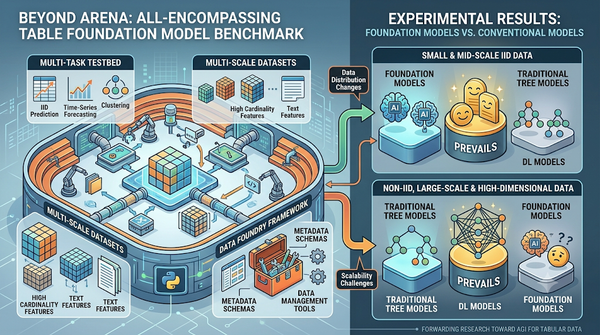
BeyondArena:首套全方位表格資料基礎模型基準平台
表格基礎模型評測散見各處,研究團隊推出 BeyondArena 整合多任務與多規模資料集,並以 Data Foundry 框架統一管理。測試結果顯示,現有模型在小型 IID 資料表現佳,卻在非 IID、大規模或高維度情境下仍被傳統樹模型領先,凸顯未來研究方向。
速報
表格基礎模型評測散見各處,研究團隊推出 BeyondArena 整合多任務與多規模資料集,並以 Data Foundry 框架統一管理。測試結果顯示,現有模型在小型 IID 資料表現佳,卻在非 IID、大規模或高維度情境下仍被傳統樹模型領先,凸顯未來研究方向。
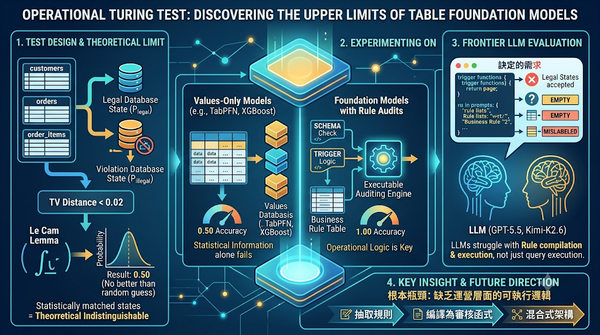
深度分析
本研究提出運營圖靈測試,以統計匹配的合法與違規資料庫狀態檢驗表格基礎模型,發現僅憑值分布的模型無法超過隨機猜測,即使提供行級存取亦無效;加入可執行的規則審核可達100%正確率;而大型語言模型即便在提示中給予完整規則,亦只能辨識不到兩筆合法狀態,顯示缺乏運營層面的可執行邏輯是根本瓶頸。
深度分析
資料串流面臨分布漂移,傳統模型需即時更新參數;表格基礎模型(TFM)則透過保留標記上下文適應。研究提出Cure策略,以不確定性門控入場與冗餘感知驅逐,同時保留近期與資訊豐富樣本。實驗在七個串流上顯示,Cure最高提升19.59分,且在不同TFM骨幹上均優於傳統方法。

深度分析
弱監督異常檢測(WSAD)研究長期分裂為三大方向:標註不完整、標註粗糙與標註有誤。WSADBench 提出第一個跨情境的統一基準,對 36 種演算法、61 個資料集、涵蓋表格、影像、文本與視訊四種模態,在統一流程下執行超過七十萬次實驗。研究揭示:三種弱監督情境間存在強關聯;
深度分析
本文報導一項首度大規模的機制性研究,針對六種最先進的表格型轉換器(Tabular Foundation Models, TFMs)逐層分析推理過程。研究以表徵相似度、分離度、探測分類器與層級干預(跳層、重複、交換)等六類實驗,揭示多數模型在深度方向存在重複與迭代精煉現象,且早期層即可形成可用表徵。

表格基礎模型
研究比較三類表格預訓練語料:網路爬取、精選資料集與參數化生成的合成表格。以表格與欄位級特徵、判別器AUC與k-NN覆蓋率衡量分布相似性。結果指出合成先驗只覆蓋真實表格狹窄區域,且在超過86000組參數搜尋下仍無法彌合差距;精選與網路語料在特徵空間大致重疊。