深度分析
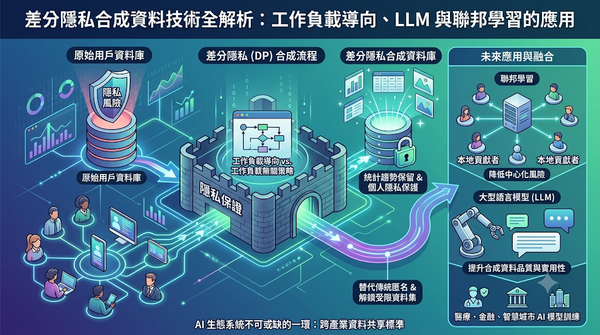
差分隱私合成資料技術全解析:工作負載導向、LLM 與聯邦學習的應用
隨著可公開的人類資料日漸枯竭,研究者轉向差分隱私合成資料以保護使用者隱私。差分隱私合成資料在保留原始資料統計趨勢的同時,提供嚴格的個人資訊保護,並可取代傳統的去識別化方法。此技術有望解鎖受限資料集,促進AI模型訓練與商業應用。未來結合聯邦學習與大型語言模型,將提升其實用性。
深度分析
隨著可公開的人類資料日漸枯竭,研究者轉向差分隱私合成資料以保護使用者隱私。差分隱私合成資料在保留原始資料統計趨勢的同時,提供嚴格的個人資訊保護,並可取代傳統的去識別化方法。此技術有望解鎖受限資料集,促進AI模型訓練與商業應用。未來結合聯邦學習與大型語言模型,將提升其實用性。

深度分析
隨著大型語言模型向文件理解延伸,解析多樣版面成關鍵挑戰。Infinity-Parser2 結合可控合成引擎與八任務聯合強化學習,打造 500 萬筆雙語資料集,同時優化版面、表格與公式解析。測試顯示其 Pro 版在 olmOCR-Bench 取得 87.6% 與 ParseBench 74.3% 新紀錄,凸顯跨任務學習效益。

深度分析
NVIDIA 以 Nemotron 系列釋出超過 10 兆前訓練標記與數百萬後訓練樣本,並提供互動式 Prompt Atlas,讓開發者能檢視與分析代理人工智慧的行為根源。

深度分析
隨著生成式AI與大型語言模型快速普及,合成資料成為隱私保護的替代方案;研究提出一套無需模型存取的稽核框架,透過真實與幻影揭露機制,結合統計假設檢定,提供比以往更嚴謹的隱私泄漏下界。此方法不依賴金絲雀插入或影子模型訓練,顯著降低計算成本,亦可作為會員推斷攻擊的實證下界。

速報
本研究提出一套自動合成資料生成方法,協助微調小型大型語言模型(LLM)以執行 Text‑to‑Cypher 解析,將自然語句轉換為圖資料庫查詢語言 Cypher。實驗涵蓋所有主流 Text‑to‑Cypher 基準測試,結果顯示,透過合成資料的訓練,小型 LLM 的準確度大幅提升,已能與大型商業模型相當。

深度分析
本報導改寫自近期 arXiv 研究,檢視大型語言模型(LLM)生成之合成專利資料,何時能改善多標籤專利分類表現。研究在助殘技術專利資料上,採用六款開源生成器、四種真實資料稀缺情境、兩種生成策略(標籤條件的完整生成與改寫)與三類分類器,並設計固定預算混合實驗與多項洩漏控制。

深度分析
隨著前沿大模型從算力綁定轉向資料綁定,高品質人類文本供給已無法跟上擴展需求。SynPro 提出一套以有機文本為基礎的合成資料生成框架,透過「重述」(rephrasing)與「重格式化」(reformat)兩種操作,並以品質、忠實度與資料影響力三項獎勵用強化學習優化生成器,持續對模型尚未吸收的內容產生具資訊量且依據原始語料的合成樣本。
深度分析
在後訓練資料生成中,直接完整輸出再篩檢會浪費大量代幣。MSIFR(Multi-Stage In-Flight Rejection)提出一種輕量、無需再訓練的多階段驗證框架,將生成流程拆成問題、部分解、完整解與最終評估四階段,於中間節點以規則式驗證器(檢查算術一致性、幻覺模式與格式違規等)即時終止低品質生成軌跡,避免繼續消耗代幣。

深度分析
半導體製程仰賴晶圓瑕疵分析但受限於資料稀缺與隱私限制。WaferSAGE以三階段合成資料、結構化評分規則與課程式強化學習,生成可評估的視覺問答對並對齊自動化評估指標。實驗顯示在本地部署下,小型視覺語言模型能接近商用大型模型的判讀表現並降低成本與隱私風險。

深度分析
高風險領域的數據私密性阻礙資料共享與模型應用;SynBench提出以差分隱私為核心的標準化評估,整合九個具領域複雜性的資料集並測量效用與保真度;實驗顯示在差分隱私約束下生成高品質專用合成文本仍未達成熟,且預訓練資料的公開成分可能削弱隱私保證。
深度分析
合成資料在隱私保護、資料擴增與模擬上被廣泛採用,但直接用於因果推論時,需保留的不只是預測準確度。本文改寫自學術研究,指出完整聯合生成器(包含 GAN 與 LLM)在重建列層級表現優異時,仍可能扭曲平均處理效果(ATE)。
合成資料
學習分析受限於學生資料的隱私與稀缺,阻礙教育科技發展。研究以一萬筆學生成績資料比較傳統重抽樣(SMOTE、Bootstrap、隨機過採樣)與深度生成模型(自編碼器、變分自編碼器、Copula-GAN)的統計擬合、效用與隱私指標。結果發現重抽樣在TSTR上接近實資料但DCR趨近0,而深度模型DCR趨近1;變分自編碼器在效用與隱私間取得最佳折衷。