
深度分析
LLM 生成程式碼的結構一致性檢測:圖形屬性圖與混合驗證框架
隨著大型語言模型輔助寫程式的普及,生成的程式碼常在編譯與測試階段通過,卻在部署後出現結構不一致的錯誤。研究以圖形一致性不變式定義八類結構失敗,建構混合驗證框架,結合靜態分析與自製跨圖偵測器。實驗顯示,多數結構缺陷逃過型別檢查與測試,且不同模型的失敗模式差異明顯,突顯專門結構驗證的必要性。
深度分析
隨著大型語言模型輔助寫程式的普及,生成的程式碼常在編譯與測試階段通過,卻在部署後出現結構不一致的錯誤。研究以圖形一致性不變式定義八類結構失敗,建構混合驗證框架,結合靜態分析與自製跨圖偵測器。實驗顯示,多數結構缺陷逃過型別檢查與測試,且不同模型的失敗模式差異明顯,突顯專門結構驗證的必要性。

深度分析
隨著大型語言模型嵌入軟體,傳統只量測程式碼的複雜度已不足。研究推出Hecate,透過Prompt‑as‑Specification同時衡量提示層與程式碼層的結構寬度,並在118個元件驗證可預測維護工作量。結果顯示提示複雜度是獨立指標,提升預測效能。

深度分析
隨著AI系統快速成長,傳統靜態分析工具難以捕捉AI專屬程式碼味道。研究提出SpecDetect4AI,使用宣告式領域特定語言自訂規則,於826個AI專案測試達88.7%精確度與召回率,顯示其在效能與可擴充性上優於CodeSmile與mlpylint。此方法結合梯度屬性與激活修補等四條管線,定位層級關鍵區段,並提供跨模型、跨任務的可重複驗證流程。
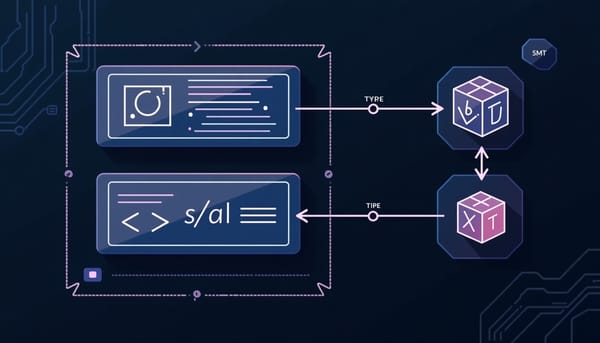
深度分析
本文針對如何把代理技能(skill)在宣告或測試等級之上,升級到可機械檢查的「formal」驗證等級提出完整方法。作者先在語義層面把技能消費分成 deterministic 的腳本端與 stochastic 的 LLM 端,將驗證目標形式化為「能力包含性」。

深度分析
在專案級單元測試自動化上,現有以執行路徑驅動的 LLM 方法常因跨類依賴、深層呼叫鏈與物件初始化複雜而失靈。本文改寫的研究提出 CAT(一種呼叫鏈感知的 LLM 測試生成法),透過靜態分析抽取呼叫鏈、建構函式與第三方依賴,將這些上下文明確注入 prompt,並以產生與修復雙階段迭代流程產出可執行測試。

深度分析
本研究針對大型語言模型在 Azure SDK 使用上的正確性提出 ACE‑Bench,一種免執行、快速判定通過與否的基準。它將官方文件範例轉為自足任務,透過正規表達式與 LLM 評審檢查 API 使用與工作流,降低測試成本並提升可重現性。實驗顯示多模型在檢索增強下表現提升,且不同模型差異顯著。