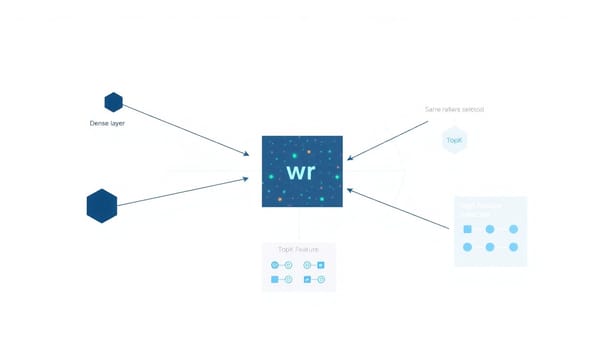
深度分析 獎勵模型可解釋性實作:Reward Lens、activation patching 與 TopK SAE 分析 在RLHF訓練下,獎勵模型定義優化目標。reward-lens將生成型可解釋工具移植到獎勵模型,以獎勵頭權向量wr為投影軸,提供Reward Lens、元件歸因、對比式激活打補丁與SAE特徵分析等套件;在兩款生產模型上實驗顯示線性歸因不能可靠預測因果重要性,強調必須同時比較觀察與因果視角。