
深度分析
Sol Video 推理引擎:代理式全堆疊加速框架提升影片擴散模型效能
隨著影片擴散模型規模擴大,推理成本同步上升。研究提出SolVideo推理引擎,結合快取、稀疏注意力、量化等技術,透過平行代理自動調校,於Cosmos3‑Super、LTX‑2.3與SANA‑Video上達兩倍以上加速,且視覺品質維持接近原始。
深度分析
隨著影片擴散模型規模擴大,推理成本同步上升。研究提出SolVideo推理引擎,結合快取、稀疏注意力、量化等技術,透過平行代理自動調校,於Cosmos3‑Super、LTX‑2.3與SANA‑Video上達兩倍以上加速,且視覺品質維持接近原始。

深度分析
在強化學習中,驗證式獎勵導致極長的思考鏈,使訓練成本高企。研究提出動態稀疏排程,透過控制稀疏與密集策略的尾部不匹配,實現2倍以上生成加速,同時保持穩定性。此方法在多尺寸Qwen3模型及程式碼任務上皆驗證有效。動態稀疏排程根據生成長度調整KV預算,確保每個代幣的低位不匹配保持在安全門檻以上。

深度分析
研究顯示,RAG生成因文件重複導致算力浪費,SIFT透過離線分析注意力不變性,只儲存高注意力位置的位元向量,於推論時稀疏計算,提升首 token 時間最高1.71倍,且精度損失不到1%。此方法減少KV快取磁碟讀寫,僅佔原始資料千分之一,適用於大型模型的即時服務。
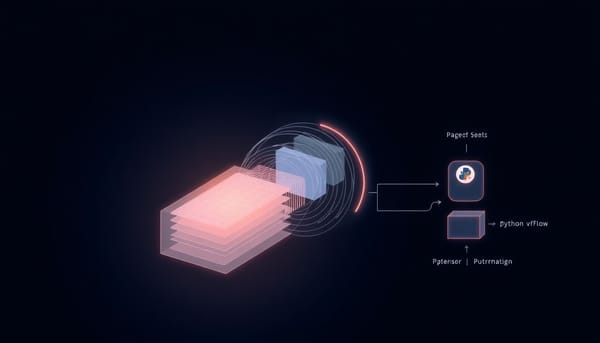
深度分析
隨著大型語言模型生成長度持續增加,稀疏注意力成為降低推論成本的關鍵。Vortex 以 Python 前端 vFlow 結合頁面式張量 vTensor,讓開發者與 AI 代理人快速設計、部署稀疏注意力,實測在 GLM‑4.7‑Flash 上提升 4.7 倍效能。此架構有望加速模型部署與自動化研究。

深度分析
Transformer 在多跳關係推理上受限於電路複雜度,需要 Ω(k) 層深度。研究提出 Rasa(Relation‑Aware Sparse Attention)加入稀疏鄰接遮罩與關係類型偏置,將注意力搜尋空間從 2^{n^2} 縮減至 2^{m}。在 MetaQA 3‑跳問題上達到 97.7% 正確率,較 EmbedKGQA 提升近 3 個百分點。

深度分析
MiniMax發表深度技術報告,回顧M2系列(含M2、M2.5、M2.7)在稀疏Mixture-of-Experts、Grouped Query Attention(GQA)與工程化路徑上的關鍵取捨;

深度分析
序列模型常對每個位置給予相同計算,忽略局部與檢索需求差異。本文改寫的研究提出 AMOR(Adaptive Metacognitive Output Router),以線性複雜度的 SSM 作為「系統1」快速處理,並用預測分布的熵當作元認知閘,只有在不確定(高熵)時才啟動稀疏注意力(系統2)。

深度分析
Transformer在語言與多模態任務上表現卓越,但面對需要沿著圖結構連續追溯關係的多跳推理仍有架構性限制。論文從電路複雜度角度指出,標準Transformer屬於TC0類別,常數深度無法解決圖連通性,因而需要隨跳數成長的層數。
深度分析
在大型語言模型處理百萬級上下文之際,密集注意力成為計算瓶頸。MISA(Mixture of Indexer Sparse Attention)提出把索引器的多個索引頭視為混合專家池,透過一個輕量的區塊匯總路由器,為每個查詢動態選取少數活躍頭部,只對這些頭進行逐詞評分,從而把每查詢的索引器成本從O(H^I·L)降到O(h·L+H^I·M)。

深度分析
一個邁阿密新創宣稱用一種稱為 SSA 的稀疏注意力架構,把注意力計算從二次方複雜度降為線性。該法以內容導向選取重要標記、避免全域比對,並在長文脈檢索與程式碼任務上報告大幅速率與成本優勢。若獲第三方驗證,將改變企業處理長脈資料的成本結構與系統設計。

深度分析
FlashAttention 受限於向量運算延遲,研究提出 VFA 透過全域最大值預計算與鍵塊重新排序,減少 rowmax 更新。結合稀疏跳過的 VSA 進一步削減開銷,實驗顯示相較基線加速近兩倍,對未來加速器效能提升具重要意義。

深度分析
影片擴散模型計算昂貴,研究者提出 PASA 以動態算力分配、分組近似與隨機路由降低成本,同時抑制時間閃爍,實驗證實可加速推論並提升畫面流暢度。