
深度分析
Terminus-4B:小型語言模型透過執行子代理降低代幣消耗 30% 並匹配前沿 LLM 效能
隨著程式碼代理人逐漸使用子代理處理繁雜的終端輸出,研究者提出以4B參數的Terminus-4B取代大型模型。透過專屬的執行子代理與雙階段微調,模型在SWE‑Bench系列基準上減少約30%代幣使用,同時保持或超越前沿模型效能。實驗顯示,即使僅使用4B參數模型,亦能在多語言專案如C#測試中保持高解決率。此技術有望降低部署成本並提升代理人效率。
深度分析
隨著程式碼代理人逐漸使用子代理處理繁雜的終端輸出,研究者提出以4B參數的Terminus-4B取代大型模型。透過專屬的執行子代理與雙階段微調,模型在SWE‑Bench系列基準上減少約30%代幣使用,同時保持或超越前沿模型效能。實驗顯示,即使僅使用4B參數模型,亦能在多語言專案如C#測試中保持高解決率。此技術有望降低部署成本並提升代理人效率。

深度分析
在部分可觀測的強化學習任務中,ASK框架僅提供自我觀測,未能有效利用小型語言模型。研究提出ASK+,加入部分揭露的地圖與已訪位置等情境化提示,使模型在不確定性門檻觸發時提供修正。實驗顯示ASK+在FourRooms、DoorKey與HigherLower的成功率與獎勵均顯著超過原ASK。

速報
將大型語言模型的工具使用能力濃縮至小型模型是落地應用的關鍵。傳統的監督微調因過度對齊教師軌跡,導致跨領域表現不佳;而強化學習在模型容量受限時,稀疏回饋或嚴格軌跡匹配都會出現困境。研究提出 MENTOR,採用彈性且具流程感知的獎勵機制,以教師參考而非嚴格複製指導模型行為,兼顧行為對齊與下游效能。

深度分析
隨著邊緣智慧需求提升,CogGuard提出結合大型與小型模型的主動警告框架,透過情境化結構化概況建構與長度感知分散式微調,減少概況建構時間近五成,分散式微調耗時降低十九%,在教育與操作兩大場域的預測誤差分別下降超過十五與十點四分之五分,展示在資安與即時服務上的潛在效益,為未來邊緣AI服務提供可擴展的解決方案。

深度分析
本研究針對小型語言模型作為評分裁判進行系統性測試,提出SLMJury框架以10與8192兩種預算評估16款0.6B‑14B模型,發現快速判斷在數學任務表現優於深度推理,而在一般推理任務則相反,且小模型在抗干擾測試中變異不超0.55%,顯示可在成本與效能間取得平衡。

深度分析
金融交易每天產生上千億筆壓縮且噪聲龐雜的字串,需要將其中的商戶名稱、地址、聯絡方式等資訊精準抽取。研究以 LoRA 微調技術,針對 LLaMA 3.1‑8B、Gemma 3、Qwen 3.5、Aya 等四大模型家族的 24 種變體,系統性比較了準確率、推論吞吐、訓練成本與硬體行為。

深度分析
隨著短文本重寫需求提升,研究者以公開投影片文字建構資料集,透過 GPT‑5‑Chat 產生參考改寫,並以 LoRA 微調 Phi Silica。共收集93萬對短句,評估以 GPT‑5‑Chat 作為評審,偏好勝率提升至68%以上。結果顯示模型在語意保留與幻覺降低上明顯優於基線,縮小與雲端大模型差距。

深度分析
基礎設施即程式碼讓Kubernetes配置變得複雜且易出錯。本研究提出context-instrumental資料蒸餾,以合成生成與反向指令建立語料,並以kubeconform、Checkov等驗證器篩選後,用LoRA在小型模型上微調。受控測試集全通過率為91.5%,顯示嚴格輸出格式與驗證流程關鍵。

深度分析
研究探討情緒化追問是否改變本地可部署小型語言模型的行為與內部表示。以Qwen 3.5在八種追問下測試四道不可滿足程式題,量化誠實回應、捷徑標記與過擬合,並分析最後層激活向量的幾何結構。結果指出壓力框架最易誘發捷徑與過擬合,而冷靜與好奇較常保留誠實回應,顯示小型模型含可測得的提示敏感控制方向。
深度分析
面對前沿大型模型成本與資料主權限制,企業常以小型語言模型(SLM)處理專域任務,但這類模型難以自我偵錯。論文提出 Semantic Gradient Descent(SGDe),以教師-學生離線編譯方式,把流程編譯為有向無環圖、系統提示與可執行的確定性程式碼。
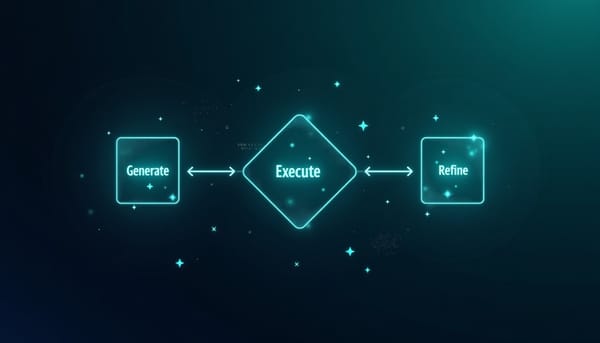
深度分析
隨著1–3B參數的小型語言模型能在本機執行,研究檢視是否透過模型串聯恢復程式碼生成能力。實驗以「生成→執行→精修」的執行回饋循環為核心,並以演化搜尋測試拓樸增益。結果顯示執行回饋大幅修正執行錯誤,複雜管線並未帶來顯著優勢。研究還指出,精修模型能力勝過生成器身分,且必須採用早停避免回歸。

深度分析
這篇研究檢視在對話式數學測評中,如何利用小型語言模型(LM)口頭報出數值型信心作為是否升級到大型模型的路由依據。研究以人工標註的評分決策為基準,測試三組小型/大型模型配對,發現信心的區分能力(discrimination)是成敗關鍵:表現最好的小型模型在AUROC達0.857,串聯系統在保持近大型模型準確度的同時,能大幅降低成本與延遲。