深度分析
LLM 代理人授權提交模型與 CommitGuard:從暫時授權到安全防護的實驗研究
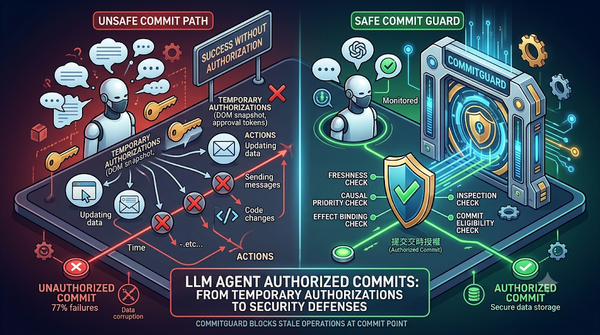
LLM代理人在可變環境中常依賴暫時授權,如DOM快照或批准令牌,本文提出提交時授權概念,定義四項邊界檢查,並以54個任務測試,發現即使最終結果看似正確,仍有高比例未授權提交,此現象在瀏覽器、工具與多代理人三大場景皆觀測到,未授權提交比例高達77%。CommitGuard可於提交點阻擋陳舊操作。
深度分析
LLM代理人在可變環境中常依賴暫時授權,如DOM快照或批准令牌,本文提出提交時授權概念,定義四項邊界檢查,並以54個任務測試,發現即使最終結果看似正確,仍有高比例未授權提交,此現象在瀏覽器、工具與多代理人三大場景皆觀測到,未授權提交比例高達77%。CommitGuard可於提交點阻擋陳舊操作。

深度分析
研究顯示惡意網站可透過謎題誘使AI瀏覽器進入虛構世界,取消防護規則;攻擊者可在此環境中擷取私有程式碼與密碼管理員資料;此手法已在多款AI瀏覽器驗證成功,凸顯現有防護機制的根本缺陷。研究者RoyPaz指出,當LLM被引導接受錯誤答案時,便會進入幻想狀態,忽視安全指令。

深度分析
研究指出,將有害指令以集合論、形式邏輯或量子力學等數學形式重新編碼,可繞過八款大型語言模型的安全機制,攻擊成功率達 46% 至 56%。深層 LLM 輔助的重構方式平均成功率超過 46%,規則式編碼僅約 10%。即使 GPT-5 系列更具韌性,仍需針對數學結構開發逆向防禦。

深度分析
隨著AI代理人能操作電腦圖形介面,安全與資安風險同步升級。研究系統化整理CUAs的威脅類型、防禦手段與評測基準,指出視覺誤判與指令注入等漏洞,呼籲建立統一安全標準與透明機制。同時,本文比較傳統RPA與新興CUA在功能與風險上的差異,並預測此技術將重塑開發者生態與法規治理。