
深度分析
以視覺等價為導向的獎勵設計—Visual-ERM 與 VC-RewardBench 評測
視覺到程式碼(vision-to-code)任務要求模型從圖表、表格與向量圖等視覺輸入重建可執行或結構化的文本表示。Visual-ERM提出一種跨模態生成式獎勵模型,直接在渲染後的視覺空間評估細緻差異,並產出可解讀的診斷回饋,克服純文本或視覺編碼相似度的局限。
深度分析
視覺到程式碼(vision-to-code)任務要求模型從圖表、表格與向量圖等視覺輸入重建可執行或結構化的文本表示。Visual-ERM提出一種跨模態生成式獎勵模型,直接在渲染後的視覺空間評估細緻差異,並產出可解讀的診斷回饋,克服純文本或視覺編碼相似度的局限。
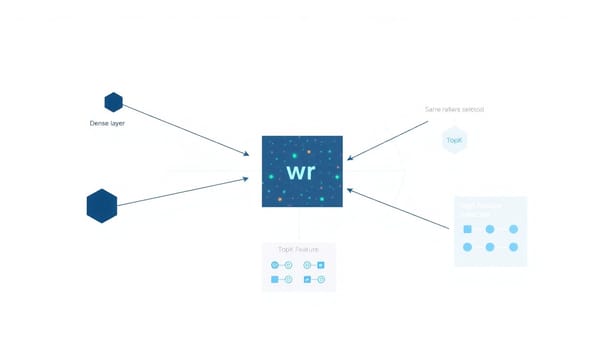
深度分析
在RLHF訓練下,獎勵模型定義優化目標。reward-lens將生成型可解釋工具移植到獎勵模型,以獎勵頭權向量wr為投影軸,提供Reward Lens、元件歸因、對比式激活打補丁與SAE特徵分析等套件;在兩款生產模型上實驗顯示線性歸因不能可靠預測因果重要性,強調必須同時比較觀察與因果視角。