
深度分析
結合 DBMS 原則的 AI 研究代理人:版本化、冪等與可追溯的 ADRS 架構
隨著大型語言模型代理人能自行提出假說、編寫程式並產出圖表,研究流程逐漸自動化。但因每一步皆為隨機 LLM 呼叫,結果不穩定且難以追蹤。本篇提出以資料庫管理系統為藍本,將研究計畫視為可版本化、確定性的資料流,引入版本、回溯與可見化機制,使系統更可靠且不浪費資源。
深度分析
隨著大型語言模型代理人能自行提出假說、編寫程式並產出圖表,研究流程逐漸自動化。但因每一步皆為隨機 LLM 呼叫,結果不穩定且難以追蹤。本篇提出以資料庫管理系統為藍本,將研究計畫視為可版本化、確定性的資料流,引入版本、回溯與可見化機制,使系統更可靠且不浪費資源。

速報
科研可重現性是關鍵。研究者打造 ReproRepo,利用 GitHub Issue 作為自然標註,評估大型語言模型找出論文與程式碼庫的阻礙。測試 1,149 篇機器學習論文,最佳模型在約 90% 論文中偵測到至少一項人類報告的問題,顯示模型在可重現性稽核上具備實用潛力。

深度分析
本篇深度報導探討代理式 AI 系統在執行過程中出現的變異現象,從基礎模型的 token 抽樣機制切入,說明隨機抽樣、決定性解碼與外部環境變化三大變異來源。

深度分析
面對人工智慧評估與研究信度危機,作者提出以隨機對照試驗為核心、結合五項原則與三十三條指引,強調以人類績效為終點、落實因果推論與透明可重複性,並針對模型版本管理、使用者互動、干擾或外溢效果與公平性評估,提供實作指引以提升結果的可比較性與政策可用性。
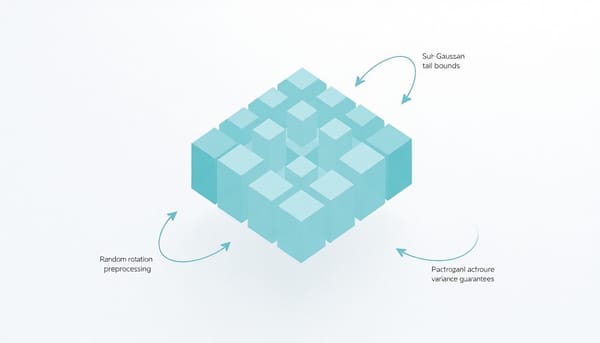
深度分析
本報告重新比對向量量化研究中的RaBitQ與TurboQuant,分析方法、理論保證與實驗複現。兩者皆採隨機旋轉與坐標量化,但在碼本設計與誤差上路徑不同:RaBitQ提出次高斯尾界達到最優位階,TurboQuant僅提供變異數界,難以直接轉成同等尾界。實驗下TurboQuant未顯著優於RaBitQ。