
深度分析
RapTB 與 SubM 雙機制破解 GFlowNet 模式崩潰:強化前綴信用分配與多樣性重播
Generative Flow Networks(GFlowNet)在微調大型語言模型時,常因前綴崩潰與長度偏誤導致模式崩潰。研究團隊提出 Rooted absorbed prefix Trajectory Balance(RapTB),透過根節點錨定與吸收後綴回傳,強化前綴層級的學習訊號;
深度分析
Generative Flow Networks(GFlowNet)在微調大型語言模型時,常因前綴崩潰與長度偏誤導致模式崩潰。研究團隊提出 Rooted absorbed prefix Trajectory Balance(RapTB),透過根節點錨定與吸收後綴回傳,強化前綴層級的學習訊號;
速報
一項由 ArXiv 發表的最新研究,深入探討了 Bellman 方程的形式根源。研究團隊指出,最優價值函數的遞迴特性源自三個核心條件:動態系統可透過充分統計量分解、回報可遞迴分解、以及不確定性聚合與前兩者相容。當這三個條件在同一狀態空間中同時成立時,Bellman 方程便自然產生;
深度分析
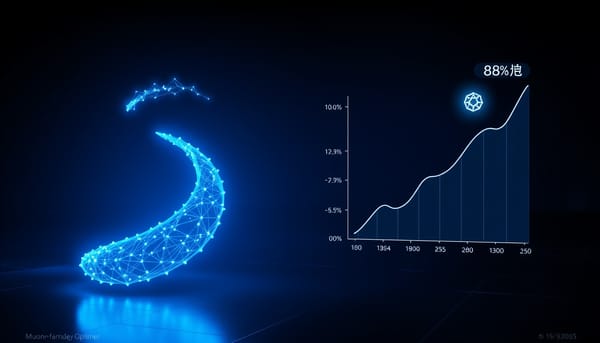
研究探討Muon優化器在稀疏回饋的長程代理強化學習中的表現,與AdamW於ALFWorld任務比較。結果顯示,在GiGPO設定下,僅對隱藏矩陣使用Muon可將驗證成功率提升約88%,且在較高學習率仍保持效能。Muon在GRPO與GraphGPO上亦有提升,於GraphGPO接近飽和時差距縮小。

深度分析
研究探討閉環知識系統在持續回饋下的飽和現象,提出三層操作框架以結構參數θ區分內部迭代與外部干預,並以度量條件與KL界定逃逸可能性,實驗顯示在LLM程式修復、稀疏回饋強化學習與貝式最佳化中提升品質。此框架亦提供跨領域診斷工具,協助開發者設計可驗證的結構干預,預測AI系統在長期迭代中的表現走向。

速報
本研究針對搜尋救援任務開發新型三層階層學習架構,結合 Hebbian 可塑性、圖形神經網路強化學習與模型無關元學習,形成反射、技能與推理三層次。架構以二十二項合約提供安全、最佳化等六項保證,並引入群體元認知,使無人機群可自我監控與策略切換,提升任務效能與韌性。

速報
本研究針對 Option-Critic 框架在強化學習中面臨的兩大挑戰——選項行為高度相似與可用選項數量縮減——提出解決方案。作者引入資訊理論式內在獎勵以及新穎的終止目標,以促進選項集合的行為多樣性。
深度分析
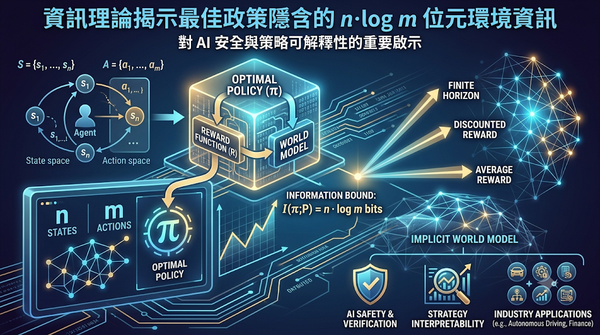
研究探討在受控馬可夫過程中,觀測一個對任意非恆定獎勵函數最優的確定性政策,可精確得知環境中 n 個狀態與 m 個動作所包含的 n·log m 位元資訊,並證明此上界適用於有限、折扣與平均獎勵等多種目標設定。此結果提供了對於「隱性世界模型」的資訊下界,對 AI 安全與策略可解釋性具有重要啟示。
深度分析
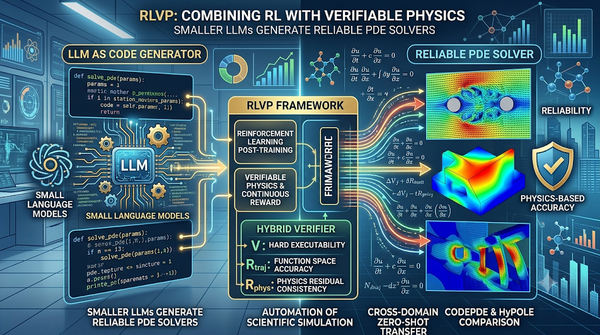
傳統偏微分方程(PDE)求解器的開發高度依賴專家經驗,而現有大型語言模型生成程式碼時,往往難以將數值可靠性內化。為此,研究提出 RLVP 框架,透過後訓練將執行結果與物理正確性轉化為連續獎勵(包含可執行性、函數空間精度與物理殘差一致性),引導模型自動生成符合科學規範的 PDE 求解器。 實驗表明,經過 RLVP 訓練的小型語言模型,在分佈內 PDE 生成的表現上超越了前沿模型的提示詞效果,並展現出跨領域的零樣本轉移能力。此研究證實了將可驗證物理回饋納入訓練的可行性,預示著 AI 科學計算未來將朝向「小模型 + 物理驗證後訓練」發展,能大幅降低開發門檻並加速自動化模擬工作流。
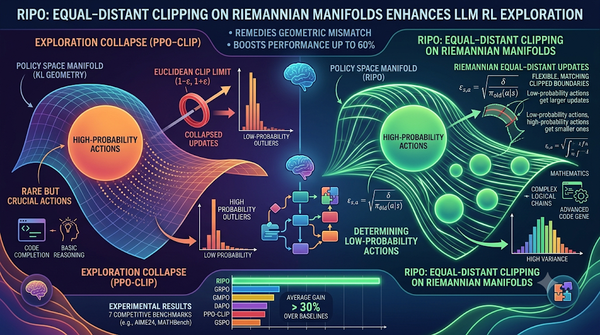
深度分析
大型語言模型的強化學習常用PPO‑Clip,但因使用歐式度量與策略流形的黎曼幾何不匹配,導致探索崩潰。研究提出Riemannian等距策略優化(RIPO),在流形上等距調整剪裁界限,使低機率動作獲得較大更新,平衡探索與利用。實驗顯示在七項競賽基準上,RIPO相較於GRPO提升最高達60%。
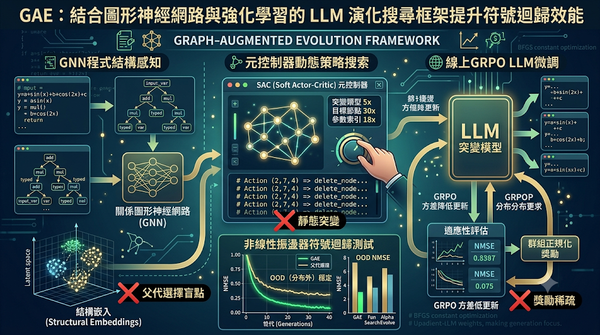
深度分析
隨著大型語言模型結合演化搜尋成為科學發現新趨勢,GAE框架透過圖形神經網路、強化學習元控制器與線上GRPO微調,解決父代選擇盲點、獎勵稀疏與靜態突變三大瓶頸,於非線性振盪器符號迴歸測試中取得最佳NMSE,顯示結構感知演化顯著提升搜尋效率與效能。

深度分析
隨著大型語言模型在多步推理上需求提升,傳統單次檢索已不足。研究提出 GRASP,透過強化學習讓模型在語意搜尋、關鍵字搜尋與段落閱讀間動態切換,僅在需要時擴充上下文。實驗顯示在 HotpotQA、2WikiMultiHopQA 與 MuSiQue 上,其檢索召回與問答正確率均超過現有單步與提示式基線。

深度分析
研究針對通用效用馬可夫決策過程加入風險感知目標,提出以熵風險度量為基礎的風險感知框架,並利用蒙地卡羅樹搜尋在線規劃求解,實驗驗證在探索、模仿學習及多目標任務中能有效平衡期望表現與風險偏好,提升策略的魯棒性,此方法亦展示於不同折扣因子設定下的穩定性,為未來風險感知決策提供實作基礎。