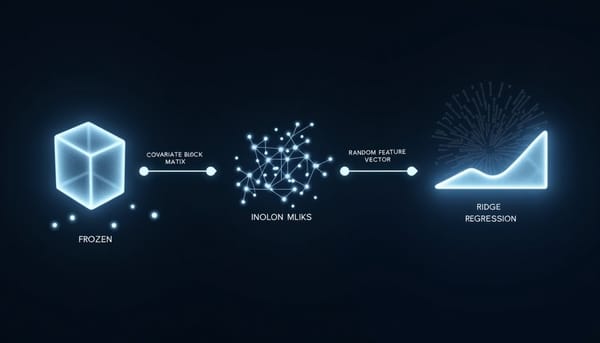
深度分析 RidgeFT:利用協方差校正與隨機特徵的持續 MGT 歸屬技術 隨著大型語言模型不斷推出,新型生成器的文字辨識成為挑戰。研究提出 RidgeFT,採用凍結編碼器、協方差校正與固定隨機特徵,僅以類別統計完成增量更新,免除舊資料重放。實驗在多主題、多模型設定下,全面提升 macro‑F1,兼顧舊類別保留與新類別適應。