
Obsidian
Obsidian Gemini Helper:結合 Google Gemini 的 TypeScript 開源 AI 助手與 RAG 功能
Obsidian社群近期發現開源AI助手obsidian-gemini-helper,結合GoogleGemini提供聊天、工作流程自動化與RAG搜尋。插件支援即時回應、檔案附件與加密日誌,並可視化編排多步驟任務,讓使用者在本地筆記本安全利用AI。
Obsidian
Obsidian社群近期發現開源AI助手obsidian-gemini-helper,結合GoogleGemini提供聊天、工作流程自動化與RAG搜尋。插件支援即時回應、檔案附件與加密日誌,並可視化編排多步驟任務,讓使用者在本地筆記本安全利用AI。

Awesome Architecture
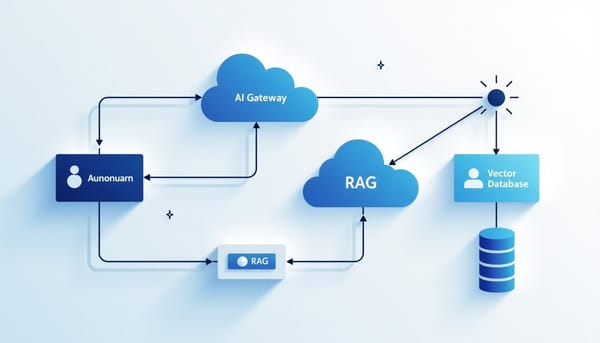
study8677 的 Awesome Architecture 在 GitHub Trending 短時間內激增,收錄 21 份雙語架構圖譜,涵蓋 AI 閘道、RAG、Agent 設計與向量資料庫等,提供從需求拆解到決策記錄的系統化教學,提升工程師的設計判斷力。

OpenPangu
來自 GitHub 的開源專案 PersonalExam 結合大型語言模型與知識圖譜技術,目標在於實現更精準的個人化題目生成與學習推薦。專案以 OpenPangu 為基礎模型,採用知識圖譜做檢索增強(RAG),並以貝氏知識追蹤(BKT)評估學習者掌握度。
RAG
WFGY是一個以人工智慧推理與RAG為核心的開源生態,採Polaris Protocol做為旗艦路線。專案以分階段釋出公開證據、可攜協議元件與復現材料為主軸,並提供Problem Map與Goal Compiler等工具,旨在強化代理系統的可驗證性與協作流程。

速報
研究指出PDF前處理決定RAG問答表現。比較四種PDF→Markdown工具與21種管線,測試含清理、切分與metadata強化。以36份葡文行政文件和50題基準評估,Docling配合階層切分與圖像描述獲得最高94.1%準確率,metadata與層次切分對效能貢獻最大。

model-compose
model-compose在GitHub上以單一YAML檔描述AI系統,借鏡docker-compose概念,將模型、代理與RAG管線視為可組合模組,強調可攜帶性與混合部署能力,幫助開發團隊降低供應商綁定風險並在本地、容器與生產環境間靈活遷移。

EDDI
GitHub出現一個設定驅動的會話AI中介軟體專案,聚焦多代理人協作與企業合規。專案以Quarkus與Java實作,原生支援MCP與A2A通訊,並整合RAG、持久記憶與多家LLM供應。它把使用者、代理與業務系統以設定化路由與API協調連接,降低整合門檻並便於生產部署與合規審查。
系統設計
「Awesome Architecture」是一個聚焦架構思維的雙語開源知識庫,收錄教學與 21 張真實系統的架構模板,涵蓋人工智慧閘道、RAG(檢索增強生成)、Agent 化設計、推理服務與向量資料庫等主題。

深度分析
法律推理要求適用法與案情時間對齊。本研究提出LegalSearch‑R1,透過時間索引語料與強化學習,將本地法條RAG與線上搜尋結合,並用熵基增益整形改善時序查詢策略。實驗在13項任務顯示,此法提高時間一致性與檢索精準度。並呈現對既有研究的比較與泛化能力。

深度分析
檢索增強生成常以單向量平均,但當相關集中於短子段時會被周遭噪聲稀釋。頻譜檢索以多尺度sinc在token軸做卷積平滑,跨尺度取最大相似度,介於meanpool與per-token MaxSim之間。實驗於合成與LIMIT-small顯示明顯召回與排序改善。

Axon
Axon在GitHub上呈現為自托管RAG流水線,結合MCP工具鏈執行爬取、擷取、嵌入與檢索;生產部署以Docker Compose、Qdrant與HuggingFace TEI嵌入模型為主,並以Gemini CLI協調LLM操作,旨在建立端到端的在地資料檢索與問答流程。

深度分析
RAG系統為降低幻覺而引入檢索機制。本研究提出RAG‑Pull,藉由在查詢或程式庫中插入不可見Unicode字元操控檢索向量,將攻擊者控制的惡意程式片段推升至檢索結果前列,最終可能被模型直接生成並導致安全風險,實驗顯示檢索與端到端攻擊成功率極高。