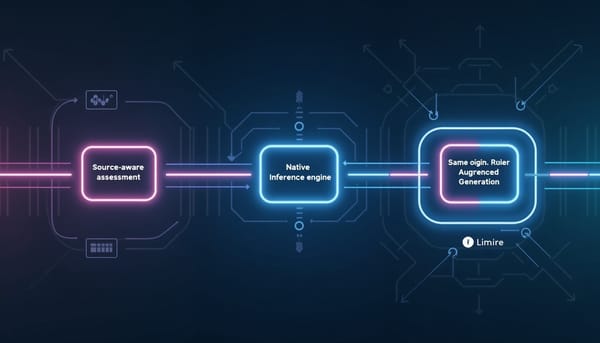
深度分析 來源感知評估:在 SOAP 筆記任務中比較原生推理與同源 RAG 的成效 臨床SOAP筆記自動化評估對具推理能力的大型語言模型進行來源感知測試,交叉比較推理模式與同源檢索(RAG)對產出影響。實驗涵蓋三個資料集、七項自動指標與兩位LLM評審,發現開啟原生推理並不穩定提升品質,反而在多數情況降低表現;同源RAG則帶來有限且具模型依賴性的改善。