深度分析
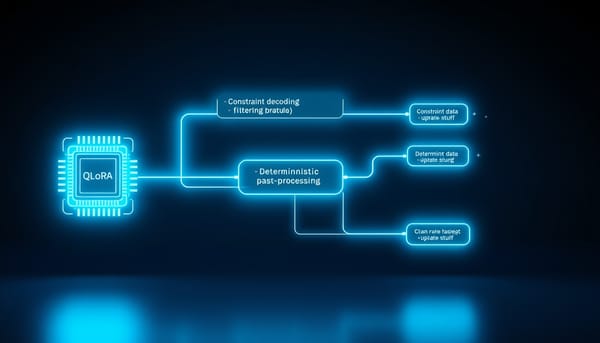
CommitLLM 三層管線:以 QLoRA 微調與限制解碼提升 Git 提交訊息格式合規率至 98%
開發者常寫「fix」等無意義提交訊息,CommitLLM 以三層管線解決:微調 Mistral-7B、限制解碼、確定性後處理。在 50 筆測試中,格式合規率達 98%,平均長度降至 37.9 字元,LLM 評分 3.68。後處理貢獻大於微調,系統可在單張 T4 GPU 運行。

深度分析
近年大型語言模型被宣稱可模擬人類認知,本文提出 LAPITHS 框架,結合最小認知格線與行為比較,發現未經特化訓練的模型亦能在兩步任務上匹配 CENTAUR,且神經對齊可由非專屬模型復現,因此,研究呼籲在評估 AI 認知聲稱時,必須加入結構性檢驗與理論嚴謹性。

深度分析
研究顯示語言模型首次在 LSAT 正式測驗中取得滿分。透過八種推理模型的對照實驗,發現思考階段的缺失會削弱正確率,尤其在邏輯推理上下降 8%。微調獎勵模型結合 Best‑of‑5 選擇,可縮小與最佳表現的差距,突顯 AI 已突破法律測驗的人類專屬門檻。