
深度分析
ASK+:透過三層情境化提示增強小型語言模型在 POMDP 任務中的表現
在部分可觀測的強化學習任務中,ASK框架僅提供自我觀測,未能有效利用小型語言模型。研究提出ASK+,加入部分揭露的地圖與已訪位置等情境化提示,使模型在不確定性門檻觸發時提供修正。實驗顯示ASK+在FourRooms、DoorKey與HigherLower的成功率與獎勵均顯著超過原ASK。
深度分析
在部分可觀測的強化學習任務中,ASK框架僅提供自我觀測,未能有效利用小型語言模型。研究提出ASK+,加入部分揭露的地圖與已訪位置等情境化提示,使模型在不確定性門檻觸發時提供修正。實驗顯示ASK+在FourRooms、DoorKey與HigherLower的成功率與獎勵均顯著超過原ASK。

深度分析
隨著推薦系統向多回合對話式代理轉型,傳統評測已無法跟上。研究推出τ‑Rec基準,以可驗證獎勵與揭露標籤機制取代主觀評分,測試六大模型在電影目錄上的偏好引導與政策遵循,結果顯示最佳模型的pass^1僅約57%,pass^4跌至約35%,凸顯可靠性斷崖。
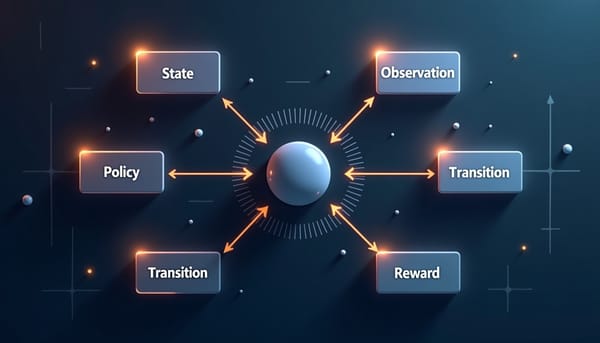
深度分析
本研究針對強化學習的分布轉移建立統一因果來源分類,從狀態、觀測、策略、轉移與獎勵五個環節辨識內外部變化,並以顯性、隱性及混合三種時間邊界描述,提供評估框架量化衝擊與恢復,預示AI系統在變動環境中將更依賴因果辨識,此分類亦能對照DCNAR與LSNM‑UV方法,突顯因果結構差異。

深度分析
2026年F1規則改變讓電能成為賽事決策核心。本研究用30狀態HMM搭配POMDP近似與DQN決策,從五項公開遙測推估對手ERS、Override Mode與胎耗。合成評估顯示ERS推斷準確率與陷阱檢測表現明顯優於單訊號門檻法,為後續博弈擴展提供基準。

深度分析
本文在二間旅館的定價模擬中揭示一種常被忽視的失效模式:單一數值回報(例如 RevPAR)可能掩蓋非市場化的定價行為。研究指出,部分觀測下的競爭者狀態會把目標行為變成分布式標的,確定性值函數或單點複製會把未解的隱含不確定性壓縮成捷徑行為。

深度分析
在黑箱大型語言模型服務中,Veroic 透過可驗證觀測與貝式信念估計回應可靠度,並在預算限制下動態決定是否升級推論路徑,實驗顯示其在品質與成本間取得更佳平衡。相較於傳統單一路徑或靜態擴容策略,Veroic 能在長期序列決策中維持風險校準,並提升多項基準的正確率。

深度分析
隨著代理型AI快速崛起,傳統以自主性與目標導向定義的代理性已不足。研究以意圖、理性與可解釋性為核心,透過主動推理的部分可觀測馬可夫決策過程,在T迷宮任務中以資訊通道容量(empowerment)測量,區分零、低與高代理性表型。結果顯示,代理性提升後,治理策略須由外部限制轉向內部偏好調整。
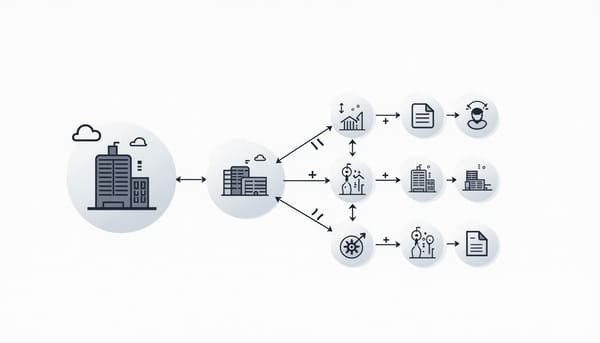
深度分析
COMPASS提出一套把提示工程形式化為認知與機率決策流程的自適應方法,採用部分可觀察馬可夫決策過程(POMDP)建模使用者潛在認知狀態(如注意力與理解),並將觀察到的互動回饋納入策略合成,動態生成或修正用於大型語言模型(LLM)的提示與說明。

深度分析
當不同計算容量的代理人共存於同一環境時,他們可形成各自的語意字母表;研究以容量衍生的語意空間 Q_{m,T}(M) 為基礎,證明低於臨界率的意圖保留通訊結構上不可行,實驗顯示傳輸率可比傳統上限低 19 倍。