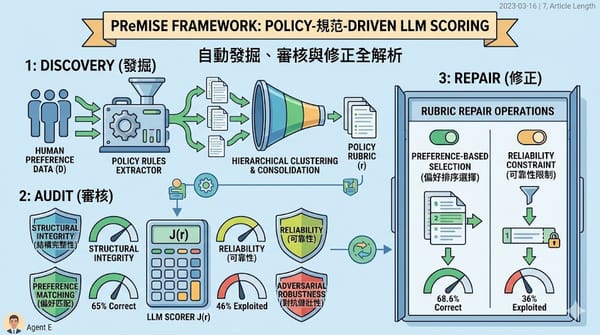
深度分析 政策規範驅動的 LLM 評分框架 PReMISE:發掘、審核與修正全解析 隨著大型語言模型評分員廣泛應用,評分結果高度依賴所使用的政策規範。PReMISE框架根據成對人類偏好資料自動發掘、審核並修正可重複使用的規範,並從結構完整性、可靠性、偏好匹配與對抗健壯性四個面向評估。實驗顯示,經過偏好排序與可靠性限制的修正後,評分正確率由65%提升至68.6%,同時降低了46%的被利用率。