
深度分析
Falcon Perception 以早期融合 Transformer 重塑視覺語言模型效能
FalconPerception以0.6億參數的早期融合Transformer取代傳統視覺管線,透過混合注意力遮罩同時處理影像與文字,於SA‑Co基準取得68.0Macro‑F1,並推出PBench診斷測試與0.3億參數的FalconOCR,顯示單模型可同時支援分割與文件辨識。
深度分析
FalconPerception以0.6億參數的早期融合Transformer取代傳統視覺管線,透過混合注意力遮罩同時處理影像與文字,於SA‑Co基準取得68.0Macro‑F1,並推出PBench診斷測試與0.3億參數的FalconOCR,顯示單模型可同時支援分割與文件辨識。
深度分析
隨著視覺語言模型被廣泛用於流程圖圖像轉程式碼,缺少參考碼使品質監控困難。研究提出以OCR產生文字作為參考的Recall_OCR,並以視覺蕴涵驗證生成內容的Precision_VE,合成F1_OCR-VE作為品質指標。實驗在FlowVQA上驗證,與真實指標相關係數分別達0.97、0.91、0.94。
Vault Extract
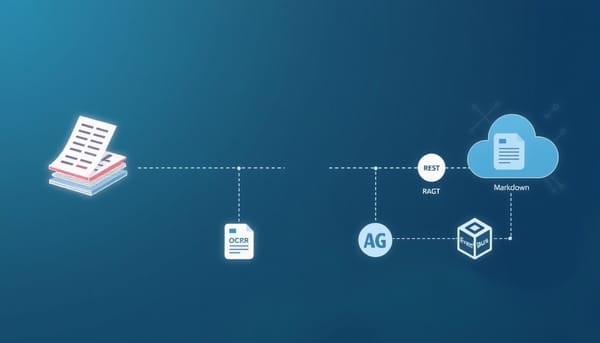
Dignite推出VaultExtract作為文件智能處理的通道層,將掃描、相片、PDF影像等內容透過OCR轉換為Markdown與結構化資料,支援REST、EventBus與未來Webhook,為RAG平台與企業系統提供可靠資料來源,預期加速AI應用的資料前置作業。
深度分析
Falcon Perception以0.6億參數的早期融合Transformer,將影像貼片與文字同序列處理,在SA‑Co開放詞彙分割基準取得68.0Macro‑F1,顯著優於SAM 3,並推出PBench診斷基準與0.3億參數的Falcon OCR,提升文件辨識效能。

深度分析
PaddleOCR3.5讓OCR與文件解析可直接使用HuggingFaceTransformers後端。只要把engine設為transformers,即可在PyTorch生態中呼叫PP‑OCRv5、PaddleOCR‑VL1.5等模型。此舉降低文件到LLM流程的整合摩擦,提升開發效率。
深度分析
Falcon Perception 針對開放詞彙分割提出早期融合 Transformer,將影像貼片與文字同序列處理並使用混合注意力遮罩,實現可變長實例輸出。於 SA‑Co 基準取得 68.0 Macro‑F1,顯示在屬性與密集場景上優於傳統管線,並提升效能。

速報
研究以視覺語言模型(VLM)檢視史料OCR表現。採用受控影像擾動與逐詞分級判定,發現多數VLM即使文字流暢也可能不以視覺為依據,錯誤具語言先驗傾向;專用OCR與通用VLM在視覺依賴上差異明顯,解碼時修正效果有限,後處理語言模型能部分補救。具有實務意涵

深度分析
研究指出,檢索增強生成(RAG)可減少大型語言模型的幻覺,針對多模態科學文件的端到端評估仍短缺。本文提出FATHOMS-RAG,結合短語召回與最近鄰嵌入分類器以區分放棄與幻覺,並發現封閉源系統在正確性與幻覺避免上顯著領先。該基準含93題、涵蓋表格、圖像與跨文檔問題,並由人類評估驗證指標效度。
深度分析
PaddleOCR推出3.5版本,把OCR與文件解析模型帶入Transformers後端。開放開發者以engine參數切換並透過engine_config配置dtype、裝置與注意力實作。此舉降低整合摩擦,讓RAG與文件AI流程更容易接入Transformers生態。

深度分析
研究指出,當文字在詞彙間插入空格造成碎片化時,大型語言模型的資訊檢索表現呈現U形曲線,稱為文字不自然谷;中度碎片化最為致命,極端碎片化則因字元層處理而部分恢復。此現象與傳統噪聲容忍測試不同,顯示模型在詞層與字元層切換時會出現不穩定區;未來需設計新基準及前處理策略,以免OCR等應用受此影響。
深度分析
FalconPerception以0.6B參數的早期融合Transformer,將影像切片與文字提示同序列處理,突破傳統視覺編碼器加文字解碼器的管線架構,在SA‑Co基準取得68.0Macro‑F1,顯示在屬性、OCR、空間與關係等複雜任務上優於SAM3。