
速報
Boogu-Image-0.1:開源多模態理解與生成模型全新突破
Boogu-Image-0.1 以開源方式提供統一多模態模型,透過提升模型理解、資料品質與訓練管線,結合推論時的代理式擴展,實現高品質文字轉圖、快速推論與雙語渲染。實驗顯示其表現可與領先閉源系統相近,且僅使用 2.08 億張影像與約 40 萬美元的訓練成本。
速報
Boogu-Image-0.1 以開源方式提供統一多模態模型,透過提升模型理解、資料品質與訓練管線,結合推論時的代理式擴展,實現高品質文字轉圖、快速推論與雙語渲染。實驗顯示其表現可與領先閉源系統相近,且僅使用 2.08 億張影像與約 40 萬美元的訓練成本。

深度分析
研究針對視訊說明文字與使用者注視資訊的關聯提出 VEGAS 指標,利用測試時的凝視資料挑選最符合觀看者注意的字幕。實驗顯示在日常活動影片上可提升檢索精準度,但在教學投影片上改善有限。此方法未需重新訓練模型,未來可結合智慧眼鏡或網頁即時注意力推估,提升個人化影片搜尋與記憶檢索。
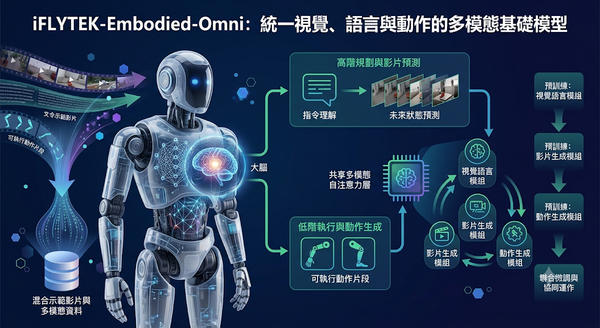
速報
為提升通用型具身代理人的指令理解與長期控制能力,研究團隊打造 iFLYTEK-Embodied-Omni,採用視覺語言、影片生成與動作生成的共享多模態自注意力架構。模型將高階規劃與低階執行分工協作,並以混合示範影片進行四階段訓練,顯著提升任務執行的準確度與穩定性。

深度分析
隨著AI代理人能自動化軟體操作,研究團隊推出DigitalCoach多模態資料集,收錄72場專家對新手的GUI教學對話,並以此評估先進模型的教學表現。結果顯示模型偏好直接指令,在真實互動測試中缺乏解釋與視覺根據,導致學習者參與度與技能保留皆較差。
深度分析
隨著生成式AI進入設計與影像領域,研究提出HumanCreativityBenchmark,透過收斂與分歧指標,分別衡量技術正確性與個人口味,並於構思、模型、精修三階段收集逾一萬五千筆專業評分。結果顯示模型在可驗證技術上高度一致,卻在美感等主觀面保持顯著分歧,提醒未來評估需兼顧可驗證與可操控訊號。

深度分析
研究指出,現有統一多模態模型在構圖辨識與生成上表現不佳。作者提出 COMPASS,透過專家錨點 τc 與 C‑MoE 注入構圖知識,並以自監督結構瓶頸實現參考圖引導的版面控制。實驗顯示,該系統在構圖分類與生成一致性上顯著優於基線,提升了圖像生成的構圖忠實度。

速報
隨著多模態模型被廣泛應用於人機協作,研究者以《Keep Talking and Nobody Explodes》開發 GPTNT 基準,測試兩代理人在時間限制與資訊不對稱下的即時溝通能力。結果顯示,現有大型語言模型無法即時拆除炸彈,顯示在狀態追蹤與錯誤恢復上仍有缺口,對未來協作 AI 發展具警示意義。

深度分析
隨著多媒體內容激增,安全風險日益複雜。Yuvion VL 以對抗式多模態設計,建構自動化資料合成與 C2FT 微調流程,提升細粒度視覺辨識與魯棒性。實驗顯示 32B 版在安全基準上超過同等規模開源模型 9.9 分,亦領先部分商業模型 6.7 分。8B 版以不足 2% 參數量,就能超越多個更大型模型的安全測試。

深度分析
Google DeepMind於2026年4月在Hugging Face釋出Gemma 4多模態模型,支援文字、影像與音訊輸入,採Apache 2授權,可在本機與邊緣設備上部署,展現長上下文與量化效能的平衡,預期將推動開發者生態與私密AI應用。

深度分析
NVIDIA於2026年4月發布Nemotron3NanoOmni,多模態模型支援文字、影像、影片與音訊,同時處理長文件與跨媒體推理,測試顯示在文件、視訊與語音基準上均領先,預示企業AI應用將更具效率與安全性。該模型在多模態推理上達到最高9倍吞吐量提升,且支援8GB以上GPU實時部署。

gpt_server
gpt_server 以 fastchat 為基礎,提供 OpenAI 規範的 Chat、Embedding、Reranker、ASR、TTS 及 Stable Diffusion 服務,支援多後端加速與模型同端口排程,讓企業能以單一服務點快速部署多模態模型,提升開發與上線效率。

深度分析
HCompany 於 2026 年推出 HoloTab Chrome 擴充功能,結合最新的 Holotron‑12B 多模態模型與混合 SSM‑注意力架構,能在瀏覽器內自動執行跨網站任務,實測顯示單顆 H100 搭配 vLLM 可將吞吐量提升逾兩倍,為企業與個人使用者帶來高效的電腦使用 AI 方案。