深度分析
TOFFEE:結合蒙特卡羅樹搜尋與自適應成本模型的高品質資料代理人軌跡合成系統
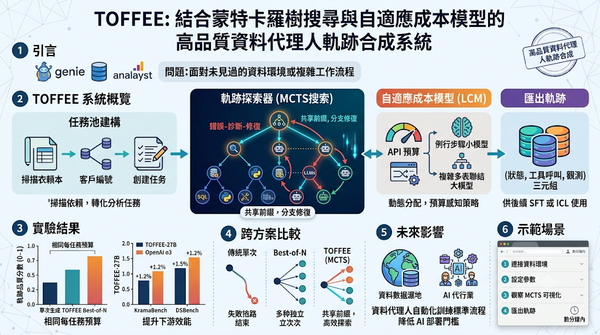
隨著大型語言模型驅動的資料代理人在企業決策中的應用日增,TOFFEE利用蒙特卡羅樹搜尋與自適應模型選擇,自動合成高品質資料代理人軌跡,並在相同預算下提升合成品質與下游微調效能。系統支援前綴重用與預算感知成本模型,降低重複計算,在KramaBench與DSBench上超越OpenAI o3等模型。
深度分析
隨著大型語言模型驅動的資料代理人在企業決策中的應用日增,TOFFEE利用蒙特卡羅樹搜尋與自適應模型選擇,自動合成高品質資料代理人軌跡,並在相同預算下提升合成品質與下游微調效能。系統支援前綴重用與預算感知成本模型,降低重複計算,在KramaBench與DSBench上超越OpenAI o3等模型。

深度分析
隨著大型語言模型驅動的資料代理人在企業環境中應用日增,現有系統難以跨資料庫泛化。研究提出TOFFEE系統,結合蒙特卡羅樹搜尋與自適應模型選擇,能在限定預算下自動合成高品質的多步驟分析軌跡。實驗顯示合成軌跡可提升微調與示範學習效能,超越現有基線。

深度分析
研究針對高維視覺環境提出COMET,以凍結的物件編碼器與transformer世界模型結合,利用動作-槽融合與因果注意力聚焦關鍵物件,於八項基準任務中顯著提升樣本效率。在多樣化的視覺控制與機械臂操作任務中,COMET的平均正規化分數超過傳統單一嵌入與其他物件導向基線。

深度分析
自動產生 Verilog/VHDL RTL 程式碼因長程推理與嚴格正確性挑戰而困難。研究提出 StepPRM-RTL,結合步驟軌跡、過程獎勵模型與 MCTS 探索,並以檢索增強微調提升中間決策品質。實驗顯示在 Verilog 與 VHDL 基準上功能正確率提升逾 10%,推理忠實度亦顯著提升,預期將加速硬體設計自動化商業化。

深度分析
隨著可控摘要需求提升,研究提出PACO框架利用自訂蒙特卡羅樹搜尋逐層調整屬性順序,無需額外微調,即可在多屬性限制下產出高品質摘要,實驗顯示即使使用1B參數模型亦能匹敵70B基線,此方法隨模型放大能進一步提升控制精度,超越所有現有競爭者。