
深度分析
Poolside 開源 Laguna S 2.1:118B 參數 MoE 編碼模型,強調透明度與低成本推論
舊金山 AI 實驗室 Poolside 發布 Laguna S 2.1 開源編碼模型,採 118B MoE 架構,僅 8B 活躍參數。在 Terminal-Bench 2.1 以 70.2% 超越 DeepSeek-V4-Pro-Max 等更大模型。該公司公開完整測試軌跡以提升可信度,並以大幅低於對手的價格策略搶攻企業自托管市場。
深度分析
舊金山 AI 實驗室 Poolside 發布 Laguna S 2.1 開源編碼模型,採 118B MoE 架構,僅 8B 活躍參數。在 Terminal-Bench 2.1 以 70.2% 超越 DeepSeek-V4-Pro-Max 等更大模型。該公司公開完整測試軌跡以提升可信度,並以大幅低於對手的價格策略搶攻企業自托管市場。

速報
研究團隊推出 Loopie,為目前最強的循環式 Transformer。該系列含 20B(2B 活躍)與 6B(0.6B 活躍)兩種 MoE 模型。Loopie 解決了循環模型擴展不如直接增加參數的難題,在同等算力下大幅超越傳統基準。2025 年 IMO 與 IPhO 中,Loopie 無工具即達金牌水準。

大佬動態
Nathan Lambert 指出 Moonshot AI 的 Kimi K3 將於 7 月 27 日開源權重。該模型為 2.8T 參數 MoE 架構,採用 KDA 混合注意力機制,支援 1M token 上下文與視覺理解。Lambert 認為此舉將重塑 AI 生態權力平衡,並可能引發新一波推理硬體需求。
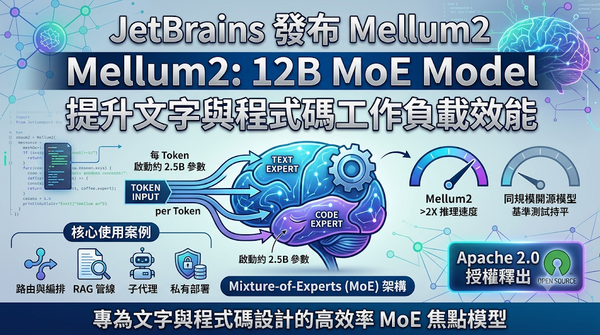
深度分析
JetBrains於2026年6月發佈Mellum2,這款12 B參數的Mixture‑of‑Experts模型專為文字與程式碼設計。模型每個token僅啟動約2.5 B參數,推理速度比同規模開源模型提升逾兩倍,且以Apache2.0授權釋出,提升部署彈性與成本效益。
深度分析
TriRoute 提出一個輕量化的共享控制器,於每層每個 token 同時決定注意力模式、稀疏專家選擇與 KV 快取位元寬度,將傳統的 MoE、MoD 與快取量化分別調校的三條路徑合併為一個全局預算下的協同決策。

深度分析
NVIDIA推出Nemotron3Ultra,結合MoE與Mamba‑Attention,預訓練20兆token並支援1百萬token上下文,推理吞吐量提升至5倍,同時保持與其他開源大模型相當的準確度。其混合Mamba‑Attention架構減少KV快取占用,並於HuggingFace公開基礎、後訓練與量化模型。

深度分析
HuggingFace推出TRLv1.0,從研究原型轉型為可在生產環境使用的穩定庫,內建超過75種後訓練方法,設計兼顧實驗與穩定性,讓開發者快速嘗試新演算法,同時降低部署風險。每月下載量突破300萬,社群貢獻者逾1.7萬人,未來將持續支援非同步GRPO、知識蒸餾與MoE,讓大型模型訓練更具彈性。

深度分析
Google 於本週開源 DiffusionGemma,將擴散技術從影像生成延伸至文字生成。模型以 Gemma 4 為骨幹,採 26B MoE 架構,僅激活 3.8B 參數,支援在消費級 GPU 上本地推論。

深度分析
Cohere 推出開源 AI 編碼代理模型 North Mini Code,旨在提供一個可本地部署的替代方案以挑戰昂貴的閉源模型。該模型採用 30B MoE 結構,專為 agentic software engineering 設計,支援 256K token 上下文視窗與終端機操作。測試顯示其輸出速度極快且吞吐量高,但內容較為冗長。此舉將使企業在建置 AI 編碼管線時,能更權衡權限、資安與推理成本。

深度分析
面對多模態模型在部署端的效能與準確性矛盾,VEN-VL提出enrich then compact原則:先以多視角知識集成(MKE)豐富視覺容量,再以階層式MoE路由(HTE)逐層濃縮強化資訊密度,並以結構資訊保留(SIP)的重建監督守護語義。結果是在僅保留少量凝縮令牌下仍顯著提升複雜視覺理解任務的表現。

深度分析
本研究檢驗MoE專家平行訓練中AlltoAll分派的兩項基本假設:系統層能否矯正路由不均與合成Benchmark是否代表真實語料。透過五套公開MoE檢查點與多種資料情境的矩陣實驗,發現EP刻度對每專家負載比影響極小,而隨機mocktoken常常高估路由不均,並建議以工作負載分群作為互連與派送設計輸入。

深度分析
Hugging Face 發布 TRL v1.0,將多年研究代碼演化為穩定的後訓練(post-training)程式庫。TRL 集合超過七十五種後訓練方法,採用「穩定核心+實驗層」並存的設計,透過刻意縮限抽象、偏好具體實作與可升級的實驗 API,降低下游破壞風險。