
深度分析
「DiT-Pruning」:針對 Diffusion Transformer 的高效模型壓縮與計算優化
Diffusion Transformers (DiTs) 雖生成品質優異但運算成本極高。本研究提出 DiT-Pruning 訓練後剪枝法,針對 DiT 特有的參數分佈,引入平方轉換以平衡權重與激活值的貢獻,並開發聚類感知剪枝粒度來優化稀疏分配。實驗證明在 FLUX.1-dev 模型達到 50% 稀疏度時,CLIP 分數僅損失 0.001,能有效降低資源消耗且不損害影像品質。
深度分析
Diffusion Transformers (DiTs) 雖生成品質優異但運算成本極高。本研究提出 DiT-Pruning 訓練後剪枝法,針對 DiT 特有的參數分佈,引入平方轉換以平衡權重與激活值的貢獻,並開發聚類感知剪枝粒度來優化稀疏分配。實驗證明在 FLUX.1-dev 模型達到 50% 稀疏度時,CLIP 分數僅損失 0.001,能有效降低資源消耗且不損害影像品質。

深度分析
研究針對 Transformer 中的前饋網路神經元,提出免訓練歸因方法,發現僅需少量前層激活與注意力輸出即可重建神經元激活,且在適度稀疏下模型困惑度不變。實驗覆蓋 GPT‑2 系列與 Qwen2.5 多種規模,顯示約 17%‑19% 神經元具可辨識的專門計算,且稀疏路徑呈次線性增長,為模型壓縮與電路解釋提供新方向。

深度分析
研究指出,MetaNCA透過本地規則在計算圖上自組織權重,能為MLP、CNN與ResNet等多種架構自動生成參數,且在MNIST與CIFAR‑100測試中達到高準確度,顯示此方法具備跨架構推廣與模型壓縮潛力。此外,訓練過程只需局部訊息,規則網路本身僅數萬參數,實現高達16倍的壓縮率。

深度分析
研究探討視覺語言行動模型的結構冗餘,提出 Drop‑Then‑Recovery 以刪除並恢復 transformer 區塊,並搭配 GateProbe 評估區塊重要性。實驗顯示語言骨幹過度冗餘,削減半數仍提升或維持表現,提示未來基準需加強語言推理測試需求。
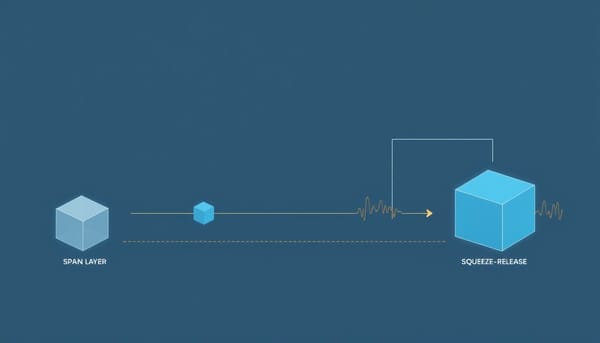
深度分析
研究背景指出傳統非結構化剪枝雖能產生稀疏權重,但模型尺寸未縮小。Squeeze‑Release 透過最小化將遮罩網路重寫為更小的密集網路,並在壓縮後以校準噪聲釋放被禁用的參數,讓多輪迭代得以進一步削減結構冗餘。實驗證實在全連接模型與現代 CNN 上分別達到39倍與14.8倍的壓縮率,且精度幾無損失。

深度分析
Vision Transformer 因自注意力計算量大而難以部署,研究提出 RAPID 以層級感知的冗餘剪枝與重要性合併減少 token。淺層使用冗餘相似度剪除重複局部特徵,深層則保留關鍵 CLS 權重的 token 並合併相似次要 token。實驗顯示在極端壓縮下,RAPID 的準確度比 ToMe 高出 4.29%。

深度分析
研究聚焦於高維線性回歸中的知識轉移,透過光譜分析揭示知識蒸餾的光譜視界擴展與弱強泛化的光譜去噪機制,證明轉移效能受隱式正則化與光譜學習速率交互支配,對未來AI模型壓縮與強化學習具重要啟示。此發現亦說明在大模型微調時,教師模型的光譜特性可作為設計新型蒸餾策略的指標。

深度分析
本研究探討全連接深度神經網路的可解釋性,將其訓練過程等同於統計物理的重正化群,針對指數族連續分布進行推導,證明最佳化後的特徵層參數即為RG固定點,此結果不僅驗證了先前在一維Ising模型上的等價性,也為未來將RG概念應用於更複雜的實際資料提供理論基礎。

深度分析
贊助搜尋面臨高吞吐與低延遲的矛盾,HARNESS‑LM以三階段訓練:先以大型SLM訓出高品質teacher,再用ℓ2對齊轉移向量到小型query編碼器,最後以對比微調精煉學生模型。實驗顯示可在保有高精準度的同時大幅降低線上延遲並帶來營收與曝光提升。

PaddleNLP
PaddleNLP是飛桿生態下的開源自然語言處理套件,提供簡易使用的LLM與SLM功能,支援多模型與分散式訓練。它整合超過百種預訓練模型與高效壓縮、推理工具,讓開發者快速建置產業級應用。自發布以來星標逾一萬,已成為中文NLP社群的重要資源。

深度分析
美國加州聯邦法院本週審理 Elon Musk 起訴 OpenAI 案,Musk 在證詞中承認 xAI 部分使用「蒸餾」技術從 OpenAI 模型訓練新聊天機器人 Grok,此舉可能削弱大型 AI 公司的算力與成本優勢。此技術亦被中國廠商利用,促使美國實驗室防範大量查詢,業界擔憂衝擊 AI 版權與治理,未來或重塑模型開發與商業化格局

深度分析
MoE 大型語言模型效能佳但資源消耗高。MoBiE 透過聯合 SVD、全局梯度融合 Hessian 與零空間誤差約束,解決跨專家冗餘與路由偏移問題。實驗顯示在 Qwen3‑30B‑A3B 上 perplexity 降 52.2%,零樣本表現升 43.4%,推論速度提升逾 2 倍。