
深度分析
WaterMoE:在 Mixture‑of‑Experts 架構中嵌入高偵測率水印技術
研究指出,隨著大型語言模型被廣泛應用,內容來源驗證需求提升。WaterMoE透過在Mixture-of-Experts模型的專家路由加入微量偏置,實現低於1%的延遲增幅,同時在偵測率上較傳統方法提升約12%。此技術有望降低水印部署成本,提升實務應用可行性。
深度分析
研究指出,隨著大型語言模型被廣泛應用,內容來源驗證需求提升。WaterMoE透過在Mixture-of-Experts模型的專家路由加入微量偏置,實現低於1%的延遲增幅,同時在偵測率上較傳統方法提升約12%。此技術有望降低水印部署成本,提升實務應用可行性。
深度分析
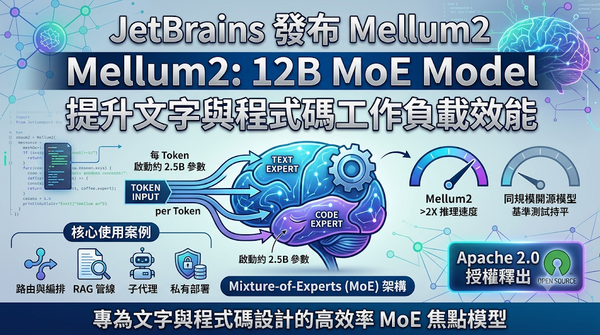
JetBrains於2026年6月發佈Mellum2,這款12 B參數的Mixture‑of‑Experts模型專為文字與程式碼設計。模型每個token僅啟動約2.5 B參數,推理速度比同規模開源模型提升逾兩倍,且以Apache2.0授權釋出,提升部署彈性與成本效益。

深度分析
MoE模型在邊緣裝置上因頻繁切換專家導致記憶體瓶頸。研究提出StickyMoE透過路由一致性損失減少切換,最高降低59%切換率並提升困惑度,同時將快取未命中下降至3.92倍。此方法僅加一個λ超參數,無需改變模型結構,可與現有快取機制結合,提升邊緣部署效能。

深度分析
隨著 MoE 模型成為前沿架構,訓練成本與記憶體需求急升。NVIDIA NeMo AutoModel 以專家平行化、DeepEP 融合 All‑to‑All 與 TransformerEngine 核心加速,讓微調速度提升 3.5 倍、記憶體下降近 30%。此效能提升使大型模型在多 GPU 環境下更易部署,預示 AI 訓練成本將持續下降。

深度分析
在資源受限的前提下,AI若聚焦於特定領域可取得更高效能。文章以無免費午餐定理、演化生物學與競爭市場為基礎,說明專化在各領域均勝過廣度,並以AlphaFold等案例證實,預示未來AI研發將更傾向於打造領域專家模型。同時指出有限算力與資料使得廣泛分配資源的效能趨於零,市場與自然選擇皆會淘汰過於分散的方案

速報
研究團隊針對在高頻寬超算叢集(如 NVIDIA NVL72/576、華為 CloudMatrix384)上部署 Mixture-of-Experts(MoE)模型時遭遇的三大通訊瓶頸,提出 UBEP(Unified‑Bus Expert Parallelism)通信函式庫。

大佬動態
Tencent 在 2026 年推出 Hy3 模型,屬 2950 億參數的 MoE 架構,活躍參數 210 億,支援 256K 上下文長度。模型在多項產品測試中優於同規模模型,且在參數規模上僅為開源旗艦模型的 2‑5 倍。Hy3 以 Apache 2.0 授權釋出,免費供開發者使用至 7 月 21 日,對 AI 生態產生顯著影響。

深度分析
JetBrains 於 2026 年 6 月正式發佈 Mellum2,一款 12 B 參數的 Mixture‑of‑Experts(MoE)模型,採用每個 token 只啟動約 2.5 B 參數的設計,使推理速度比同規模開源模型提升逾兩倍,並以 Apache 2.0 授權釋出。該模型聚焦文字與程式碼工作負載,適用於路由、檢索增強生成(RAG)與私有部署等高頻 AI 任務,為開發者提供更快且可自行管理的選項。

深度分析
過去開放式模型因授權限制無法部署於歐盟、英國與韓國等地,Tencent於2026年以Apache2.0授權釋出2950億參數的Hy3,主打可靠性與部署成本優勢,並在搜尋與工具導向工作負載上超越同類模型。Hy3將幻覺率降至5.4%,且可在符合美國出口規範的NvidiaH20-3eGPU上高效運行。

深度分析
Meituan於6月公開LongCat-2.0,1.6兆參數MoE模型支援1百萬token上下文,完全使用國產ASIC訓練。此舉挑戰NvidiaGPU壟斷,同時在美國限制西方模型的背景下提供低成本開源選項,並以每百萬token低至0.30美元的價格提供,降低開發成本。

深度分析
JetBrains 於 2026 年 6 月正式發布 Mellum2,這是一款 12 B 參數的 Mixture‑of‑Experts(MoE)模型,專為文字與程式碼工作負載設計。模型每個 token 僅啟動約 2.5 B 參數,使推理速度較同規模開源模型提升逾兩倍,且採用 Apache 2.0 授權。

深度分析
隨著 MoE 模型成為前沿架構,HuggingFace Transformers v5 引入專家後端與動態權重載入。NVIDIA NeMo AutoModel 透過 Expert Parallelism、DeepEP 與 TransformerEngine 核心,將微調吞吐量提升 3.4‑3.7 倍、記憶體降低 29‑32%。此效能突破讓 550B 大模型在 16 節點上可完成全參數微調。