
深度分析
MiniMax‑M2(MoE):以迷你啟動、MTP 與 Forge 擴展 192K 上下文的代理式 AI 實務化
MiniMax‑M2 系列提出以 Mixture‑of‑Experts(MoE)與「迷你啟動」為核心的設計路線,主張在每個 token 僅啟動小量參數即可達到實務級別的代理式智慧。
深度分析
MiniMax‑M2 系列提出以 Mixture‑of‑Experts(MoE)與「迷你啟動」為核心的設計路線,主張在每個 token 僅啟動小量參數即可達到實務級別的代理式智慧。
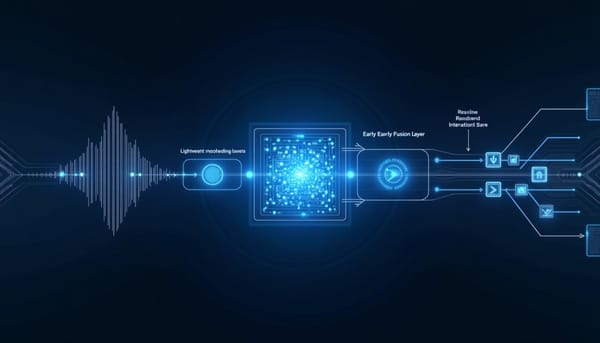
深度分析
Thinking Machines發布互動模型研究預覽,提出把互動性視為模型的原生能力,改變過去「輪替式」的輸入—處理—回應流程。該架構以全雙工、多流微回合設計,將音訊以dMel、影像以小貼塊投入輕量嵌入層,採編碼器免除的早期融合從頭共同訓練,並以互動模型與後台模型雙系統分工,達成同步聆聽與回應、同時維持後台深度推理。

深度分析
研究提出一個無因次控制參數E=T·H/(O+B),把路由溫度、路由熵權重、oracle監督權重與負載平衡權重合成一個「探索預算」。作者在視覺與語言模型上做12組受控實驗,發現當E≥0.5時可保證零「死掉的專家」,因此不再需要手工的負載平衡輔助損失。

深度分析
太空平台以持續日光供能成為運行大型語言模型的新場域。本研究提出Space-XNet,將MoE模型沿軌道環形切分成多層子網並優化專家映射。策略揭示頻繁被激活的專家應映射至預期路徑延遲較低的衛星,並以層級分割配合環形流水線降低延遲。實驗在千顆衛星構型下對特定MoE模型展現至少三倍延遲改善。

深度分析
DeepSeek發布DeepSeek‑V4,帶來原生百萬代幣上下文與1.6兆參數的MoE設計。它透過混合注意力、Manifold‑Constrained Hyper‑Connections與新優化器,大幅壓縮KV快取與推理成本,同時以MIT開放權重釋出。結果是多項代理與長上下文任務上接近閉源領先模型,並將高端模型的經濟門檻往下移動。

深度分析
Moonshot AI公開釋出Kimi K2.6,一款定位為長時間自主處理複雜軟體工程問題的原生多模態Mixture-of-Experts(MoE)代理模型。K2.6在架構上將視覺能力內建於模型、支援超長上下文,且透過專家路由在推理時只啟動部分參數以降低計算負擔。

深度分析
OpenMythos 是一個以 PyTorch 實作的開源重構專案,嘗試把 Claude Mythos 解讀為一種「循環深度變壓器(Recurrent-Depth Transformer, RDT)」。