深度分析
多智能體數學推理:評審者精度高不等於採納率高,研究揭示批評轉化才是關鍵
一項針對4,181道奧數題的研究發現,多智能體系統中專門評審者的錯誤檢測精度雖高(0.861 vs 0.644),但批評被後續答案採納的比例卻遠低於廣播式討論(0.336 vs 0.935),導致最終解題率反而落後。研究指出,評審者精度與批評採納是兩個可獨立測量的維度,設計時須同時關注。
深度分析
一項針對4,181道奧數題的研究發現,多智能體系統中專門評審者的錯誤檢測精度雖高(0.861 vs 0.644),但批評被後續答案採納的比例卻遠低於廣播式討論(0.336 vs 0.935),導致最終解題率反而落後。研究指出,評審者精度與批評採納是兩個可獨立測量的維度,設計時須同時關注。
深度分析
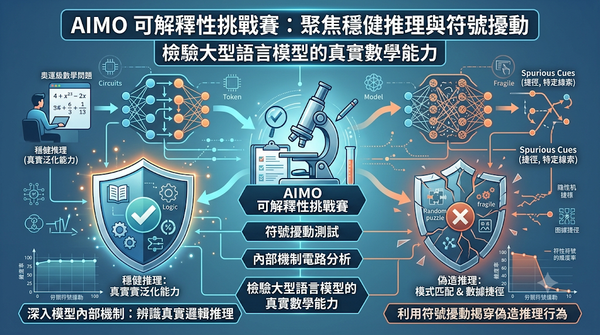
面對大型語言模型在數學基準測試中的高分,研究人員啟動 AIMO 可解釋性挑戰賽,旨在區分真正的邏輯推理與偽造的捷徑。該賽事透過提供奧運級數學問題及其符號表示,要求參賽者分析模型內部機制以辨識穩健推理。初步測試顯示,即使是前沿模型在面對簡單的符號擾動時,正確率也會大幅下降。這將推動 AI 可解釋性研究,確保高風險推理系統的可靠性與泛化能力。
深度分析
隨著大型語言模型應用於研究級數學推理,協調多代理並管理中間結果成挑戰。Danus 以共享事實圖作為全域記憶,主代理規劃、工作代理平行搜尋、無狀態驗證器核對,將證明片段組成有向無環圖。實驗顯示在代數幾何、奇點理論與組合學六個案例中,系統能在數天內產出完整論文,證明事實圖編排可提升長程數學問題的可擴展性。

深度分析
本研究利用JohnO’Bryan數學競賽題庫,將DeepSeek‑R1大模型的思考鏈以CoT方式蒸餾至Qwen2.5‑7B,透過LoRA早停微調將正確率提升至69.43%,在MATH‑500上達73.1%。實驗顯示,回應字數低於約50‑100詞會使正確率跌至41.9%,且約40%錯誤源於格式問題,提示可透過後處理提升效能。

深度分析
本研究探討以較小、領域專精但錯誤的草稿模型,透過不匹配的方式注入強化學習上下文,提升Mathstral-7B在MATH-500與AIME2025/2026的通過率,最終達到71.98%的最高成績,顯示此弱到強激發策略能擴展模型推理能力。此結果挑戰了僅能銳化模型模式的既有觀點。

深度分析
本研究聚焦於長序列推理任務中 On‑Policy Distillation(OPD)容易因學生策略漂移而失效的問題,提出一種輕量級的區塊式政策漂移門控機制。

速報
隨著推理型大型語言模型需求增加,傳統自注意力在長上下文下的計算成本呈二次方成長。

深度分析
這篇研究以八十道競賽題與二百一十七個AoPS策略族群,建立策略層級的評估框架;透過多模組標註與人類仲裁,比對四款前沿大型語言模型在單一答案與多策略提示下的行為。結果顯示:雖然最終答案正確率高,但模型恢復的人類策略遠低於參考集合,幾何與數論差距尤大,重複採樣也只有遞減的新增策略收益。

深度分析
大型語言模型在數學題上常出現能背出定義卻無法正確應用概念的落差。CORE(Concept-Oriented REinforcement)提出以人工驗證的教科書概念—題目對齊資料為核心,透過自動生成概念對齊小測、在生成階段注入簡短概念提示、以及在訓練中採用軌跡替換或KL正則化三種機制,將概念訊號變成可控的強化學習監督。

深度分析
Intel推出DeepMath,結合Qwen3‑4BThinking與GRPO訓練,模型產生簡短Python片段於沙盒執行,減少輸出長度最高66%,同時提升答題正確率。在MATH500、AIME、HMMT、HLE四大數學基準測試均表現優異。

Diffusion Language Models
研究人員提出 S³ 分層縮放搜尋技術,透過在擴散語言模型的去噪過程中動態分配推理計算量,取代傳統的末端採樣,顯著提升了模型在數學推理與邏輯任務中的表現,為擴散模型在語言生成領域的測試時縮放提供了新路徑。