
深度分析
低資源語言教學機器人:結合 WordNet、4‑bit 量化與 LoRA 的對話式 AI 流程
低資源語言缺乏大規模語料,研究以印地語詞彙網轉換 125 萬指令回應對,微調 12 億參數模型,教育聊天機器人取得 91 分教學效能,證明結構化知識可替代大量語料,此管線可延伸至所有具詞彙網的語言,為數百低資源語言提供可行的 AI 開發路徑,並與教育應用深度結合,提升學習成效。
深度分析
低資源語言缺乏大規模語料,研究以印地語詞彙網轉換 125 萬指令回應對,微調 12 億參數模型,教育聊天機器人取得 91 分教學效能,證明結構化知識可替代大量語料,此管線可延伸至所有具詞彙網的語言,為數百低資源語言提供可行的 AI 開發路徑,並與教育應用深度結合,提升學習成效。

深度分析
本研究針對少樣本 In-Context Learning(ICL)在跨語言情境下的來源語言選擇進行系統性實驗,涵蓋七項任務、六種大型語言模型以及十八種語言。結果顯示,傳統上認為的語言相似度與高資源語言(如英語)並非最佳來源;相反,低資源、非拉丁文字的語言往往能提供更佳的跨語言傳遞效能。

深度分析
隨著低資源語言缺乏對話式語音資料,研究提出利用大型語言模型產生情境對話並映射說話者屬性至TTS聲音,合成多說話者對話音檔。實驗在匈牙利BEA‑Dialogue基準上顯示,合成對話可提升辨識準確度,且在僅67小時真實資料與636小時合成資料的配置下,優於使用2700小時匈牙利語音的零樣本模型。

深度分析
研究指出,多語言大型語言模型在低資源語言的安全拒絕失效,並非缺少有害表示,而是校準門檻偏移。透過少量目標語言範例重新校正高資源門檻,即可大幅提升拒絕率,同時保留指令完成能力。此方法僅需1至4筆範例即可完成校正,顯示低資源安全問題可藉現有表示修正,降低大量語料標註成本。

深度分析
大型語言模型因英語為主的訓練資料,在非英語查詢上表現下降。研究提出EmCei,先抽取文化說明再以LLM‑as‑Judge挑選回應,提升多語言正確率,尤其在低資源語言上提升逾30%。實驗在四個多語言測試集上顯示,平均提升16.4%,低資源語言提升逾30%,且兼容多種主流模型。
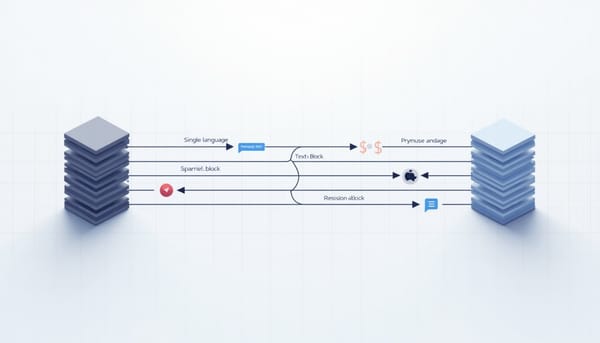
SG‑SRL
在低資源語言生成中,目標語平行資料稀缺,但來源語單語料豐富。

深度分析
美洲NLP2026文化影像標註任務挑戰低資源族語與文化語域,佛羅里達大學Gators提出雙階段流程:先以西班牙文由視覺語言模型生成中介說明,再以檢索增強的多示例提示由大型語言模型進行長上下文翻譯。實驗顯示對若干目標語言在開發集與測試集上均明顯優於基準,且檢索與合成資料在成效中扮演關鍵角色。
深度分析
本研究比較目錄與學術文獻中文件可見性的差異。採用資源密度指數RDI,按每百萬講者標準化目錄計數,再以引文挖掘驗證文獻中流通的語言別資料集。結果發現大量講者語言在主要目錄上近乎不可見,卻在研究引用裡能找到可驗證的資料集。顯示稀缺部分源於文件化與可發現性的缺口。

深度分析
研究指出多語言ASR在低資源語言因配對音檔與逐字稿不足而表現受限。WorldSpeech從議會記錄、國家與國際廣播及公域有聲書匯整並標準化資料,採用自動對齊流程,對首輪配對結果微調ASR再重對齊以回收更多對齊時數。實驗顯示微調後WER大幅下降,提升低資源語言訓練資料可用性。