
深度分析
模型合併 vs 聯合多任務強化學習:任務向量幾何分析揭示兩者表現無顯著差異
一項研究在 AppWorld 基準上比較模型合併與聯合多任務強化學習,發現合併後的專家模型在任務目標完成率上與聯合訓練模型無統計差異。任務向量幾何分析顯示專家向量近乎正交,導致支援集或符號合併方法退化為均勻平均。結果表明在該設定下合併足以匹敵聯合訓練,但需注意指標敏感性。
深度分析
一項研究在 AppWorld 基準上比較模型合併與聯合多任務強化學習,發現合併後的專家模型在任務目標完成率上與聯合訓練模型無統計差異。任務向量幾何分析顯示專家向量近乎正交,導致支援集或符號合併方法退化為均勻平均。結果表明在該設定下合併足以匹敵聯合訓練,但需注意指標敏感性。
深度分析
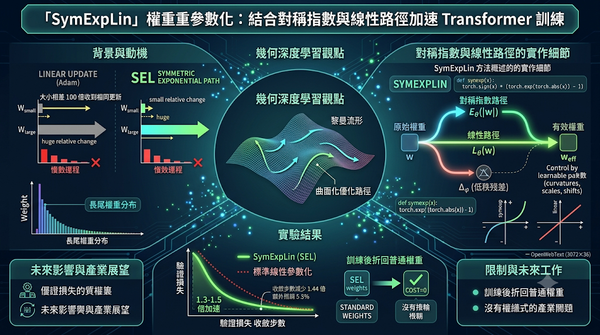
研究發現,Transformer訓練的權重分布呈重尾,線性參數化使大、小參數的相對更新差異極大。作者提出SymExpLin(SEL),結合對稱指數與線性雙路徑,使更新在對數空間呈比例放大。實驗顯示SEL在多種模型規模上將驗證損失收斂步數縮短約1.3‑1.5倍,且訓練結束後可折回標準權重,成本不變。

深度分析
IBM於2026年發表Granite4.03BVision,針對企業文件的表格、圖表與鍵值對進行深度視覺語言解析。模型結合ChartNet合成圖表資料與DeepStack視覺特徵注入,提升精準度。測試顯示在圖表與表格基準上領先同類模型,預計加速企業文件自動化流程。

深度分析
面對企業文件中複雜圖表與表格的解析難題,IBM 推出 Granite 4.0 3B Vision 多模態模型。該模型透過 ChartNet 百萬級合成數據集強化圖表推理,並採用 DeepStack 架構將視覺特徵分層注入,以兼顧高層語義與精細空間細節。實驗結果顯示,其在圖表摘要與表格提取基準測試中表現卓越,能有效將複雜視覺資訊轉化為結構化數據,為企業自動化文件處理提供更高效的輕量化方案。

深度分析
針對多語言 AI 常以英文思考再翻譯成目標語言的問題,TÜDÜM 專案利用 Qwen3.5-27B 建立土耳其語推理管線。該方案先透過 LoRA 進行監督式微調以強制思考路徑土耳其語化,隨後導入 GRPO 強化學習優化數學表現。實驗發現 SFT 能有效將思考過程轉為土耳其語,雖導致整體準確率下降,但 RL 可部分恢復數學能力。

深度分析
在製造業領域,商業資料常雜訊多、格式不一,導致模型適應困難。研究提出 CLAP閉環訓練‑評估‑釋出流程,將原始資料轉為 SFT、GRPO、評估與門檻資產,並以風險診斷與應用鏈回放決定適配器是否上線。實驗顯示平均分數略升但批次回退仍存,證明僅憑離線分數不足以保證上線效果。

深度分析
隨著參數有效微調(PEFT)成為調整開源模型的主流,LoRA仍佔據絕大多數使用率;HF以統一API提供多種PEFT方法,基準測試發現OFT、BEFT等在記憶體與準確度上可優於LoRA。此結果提醒開發者在選擇微調技術時,應根據效能與資源需求權衡,而非預設LoRA為唯一選項。

深度分析
隨著大型語言模型微調成本高漲,研究提出以控制理論為基礎的Mixture‑of‑Control(MoC)框架,將每層的低階控制視為專家,透過稀疏門機制在全模型層間傳遞全域訊號,同時保留區塊本地調整。實驗在多項NLU與NLG基準上皆超越既有的狀態式與參數有效微調方法,且記憶與計算開銷與LoRA等方案。
深度分析
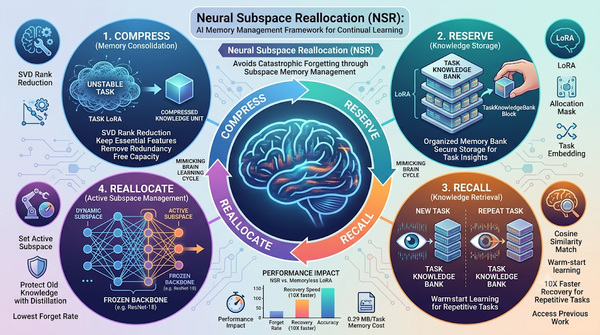
針對人工智慧持續學習中的災難性遺忘問題,研究團隊提出 Neural Subspace Reallocation (NSR) 框架。該技術將 LoRA 模組視為可壓縮且可檢索的記憶單元,透過 SVD 壓縮與 TaskKnowledgeBank 儲存,並利用相似度檢索來溫啟動新任務或恢復舊任務。實驗結果顯示,NSR 能將重複任務的恢復時間縮短 10 倍,且在多項基準測試中展現出最低的遺忘率。

深度分析
低資源語言缺乏大規模語料,研究以印地語詞彙網轉換 125 萬指令回應對,微調 12 億參數模型,教育聊天機器人取得 91 分教學效能,證明結構化知識可替代大量語料,此管線可延伸至所有具詞彙網的語言,為數百低資源語言提供可行的 AI 開發路徑,並與教育應用深度結合,提升學習成效。
深度分析
在參數高效微調領域,LoRA佔據近九成使用率,但HuggingFace針對LLM數學推理與影像生成兩項基準測試,發現BEFT、OFT等技術在記憶體需求與測試分數上均可優於LoRA,說明選擇PEFT方法時應根據效能與資源權衡,而非盲目預設LoRA為唯一選項。

深度分析
隨著生成式音樂模型多半只能離線渲染,本研究提出資料無需的串流一致性蒸餾技術,將教師模型的多步預測壓縮為單步學生模型,實現低延遲即時互動。實驗證明在保持音色與節奏穩定性的同時,能於實時因子低於0.1的條件下流暢生成音樂,為 AI 與人類共創開闢新可能。