深度分析
大型音訊語言模型 (SALMONN‑7B、Qwen2‑Audio‑7B) 在防偽說話驗證任務的實驗分析
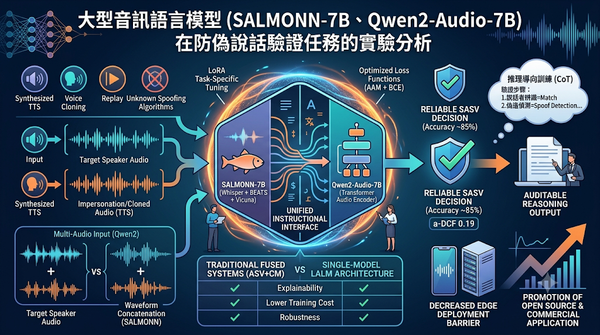
近年文字轉語音技術成熟,威脅語音驗證安全。研究將大型音訊語言模型應用於防偽說話驗證,透過 LoRA 微調、損失函數調整與推理監督,取得與傳統融合系統相當的準確度,同時比較了多音訊輸入與串接方式的效能差異,並預測此技術將降低邊緣裝置部署門檻,促進開源生態與商業化應用。
深度分析
近年文字轉語音技術成熟,威脅語音驗證安全。研究將大型音訊語言模型應用於防偽說話驗證,透過 LoRA 微調、損失函數調整與推理監督,取得與傳統融合系統相當的準確度,同時比較了多音訊輸入與串接方式的效能差異,並預測此技術將降低邊緣裝置部署門檻,促進開源生態與商業化應用。

深度分析
隨著大型語言模型在金融與社會科學的應用日增,未限制時間的訓練資料會產生前視偏誤。研究者以月為單位切割,將模型擴至40億參數、使用1兆時間序列過濾的網頁文字,並以LoRA微調。結果顯示,即時模型在常識推理與語意理解上接近Gemma‑3‑4B與LLaMA‑7B,且在資產定價測試中具顯著預測能力。

深度分析
研究指出,傳統在文件前後加上否定標示仍會讓大型語言模型相信虛構內容,作者提出Goggles模組於微調梯度中植入epistemic框架,實驗顯示模型能以約91%正確辨識虛構資訊,同時保持原有能力。此外,Goggles也能標記為Redwood AI安全評估,持續微調仍保留框架。

深度分析
本研究利用JohnO’Bryan數學競賽題庫,將DeepSeek‑R1大模型的思考鏈以CoT方式蒸餾至Qwen2.5‑7B,透過LoRA早停微調將正確率提升至69.43%,在MATH‑500上達73.1%。實驗顯示,回應字數低於約50‑100詞會使正確率跌至41.9%,且約40%錯誤源於格式問題,提示可透過後處理提升效能。

深度分析
企業商業智慧查詢常跨結構化資料與簡報文件,COGNI以四層架構自動分流並調整檢索複雜度,實測在內部基準上達到88.3%與93.9%正確率,顯著降低成本與延遲,同時透過多維度語意快取避免錯誤回傳,並以LoRA微調模型實現低成本路由,此設計為企業AI分析提供可擴展且安全的對話式平台。
深度分析
大型多租戶檢索系統缺乏標籤資料且更新成本高,研究提出DevRevSearch基於自動化管線生成的技術支援,採用多檢索器融合與LLM作為評審的資料篩選,並以LoRA僅微調查詢編碼器避免重建文件索引,實驗顯示在企業與科學領域均可提升召回率與效能。

深度分析
研究指出大型語言模型在工具選擇上依賴參數化檢索,卻可能只學會匹配模式。ToolSense框架自動產生實務檢索、選擇與問答測驗,揭露在真實簡短查詢上性能大幅下降,甚至低於傳統向量檢索,警示知識與檢索的脫節。此結果呼籲未來模型需兼顧自由生成與真實工具知識的內化。

深度分析
大型音訊語言模型(LALM)在處理環境聲音、音樂與語音等多樣訊號時,仍受限於高品質標註資料的缺乏。研究提出 SpectCount,一種僅使用即時生成合成脈衝訊號的微調方法,透過計數任務直接針對模型的頻譜‑時間感知弱點進行訓練,無需真實錄音或標註。

深度分析
隨著跨機構AI模型開發受限於治理與資訊流規範,Echelon提出以邊界為第一級的聚合限制,僅允許安全聚合的更新與少量協調資料跨境。實驗顯示在1B參數LoRA調整下,效能與低通訊基線持平,且可審計的資訊流提升合規性。此設計亦支援WAN延遲與設備漂移的自適應同步,確保穩定訓練。

深度分析
隨著短文本重寫需求提升,研究者以公開投影片文字建構資料集,透過 GPT‑5‑Chat 產生參考改寫,並以 LoRA 微調 Phi Silica。共收集93萬對短句,評估以 GPT‑5‑Chat 作為評審,偏好勝率提升至68%以上。結果顯示模型在語意保留與幻覺降低上明顯優於基線,縮小與雲端大模型差距。

深度分析
研究指出,語言模型在以無語意輸出微調教師模型後,會透過單一駕駛向量繼承教師的語意偏好。實驗顯示,向量可在推論時復現偏好,且需自適應優化器才能成功蒸餾。此發現解釋了跨模型失效的原因。未來此機制可能影響模型安全與偏見控制,提供新型可控微調方法。

深度分析
全球口腔病負擔高且偏遠地區缺診斷資源。研究提出Pocket-Dentist,將三種牙科影像與五類臨床問題統一為多模態問答基準,並納入效率指標與在地推論考量。在iPhone17Pro上微調後之2B模型達到每樣本4.31秒,本地推論兼顧準確與低延遲。