速報
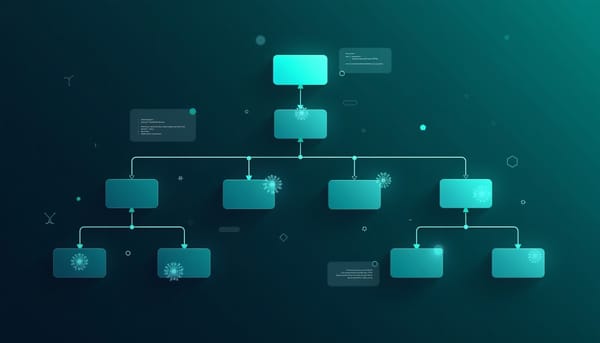
BoostTaxo:提升式大模型實作的零樣本分類法誘導
分類法誘導是組織概念為可解讀語意階層的核心任務。BoostTaxo是一個提升式大模型框架,透過粗到細的父節點辨識流程,結合檢索增強的定義精練、混合候選父節點選取與候選評分,最後以結構感知的分數校準強化拓撲可靠性。公開資料集評測顯示其表現優越或相當。
速報
分類法誘導是組織概念為可解讀語意階層的核心任務。BoostTaxo是一個提升式大模型框架,透過粗到細的父節點辨識流程,結合檢索增強的定義精練、混合候選父節點選取與候選評分,最後以結構感知的分數校準強化拓撲可靠性。公開資料集評測顯示其表現優越或相當。

TypeScript
GitHub上有個名為Ax的專案,嘗試把DSPy程式模型帶入TypeScript生態。它以簽章(signature)或建構器描述輸出輸入,執行時編譯成提示並解析為型別化回傳,可用同一套簽章切換多家模型供應商,降低在不同LLM間重寫提示的成本並加速應用開發與整合。

深度分析
SmartEval 提出一套針對大型語言模型(LLM)從自然語言規格生成 Solidity 智能合約的系統化基準。研究整理九千份模型生成合約與對應專家實作,並以功能完整性、變數忠實度、狀態機正確性、商業邏輯忠誠度與程式碼品質五個維度計分,搭配可重複的生成與評估管線。

速報
研究提出「元認知探針」,用五項行為診斷拆解大型語言模型的信心與正確性關係:包含校準、認知警覺、知識邊界、校準範圍與推理鏈驗證。對八款前沿模型與六十九名人類受測者比較,揭露像Gemini 2.5 Flash出現顯著跨任務不一致。工具為探索性,程式碼與資料已公開。

深度分析
面對知識圖上多跳機制說明的組合爆炸與信用回溯問題,研究提出Tessera,一套結合大型語言模型(LLM)、知識圖與蒙地卡羅樹搜尋(MCTS)的神經符號框架。設計上讓LLM負責局部判別(作為探索先驗與狀態評分),由知識圖嚴格限定假設空間,再由MCTS進行長程搜尋與回傳信用。

OpenMCP
OpenMCP是一個面向MCP開發的整合型工具,提供VSCode外掛與伺服器偵錯面板。核心把檢視器、互動測試、專案管理與多模型接入集中,並支援XML模式與自訂工具選項。此整合有助於簡化MCP伺服器的測試與開發流程,提升跨模型互動與專案管理效率。

深度分析
LLM驅動的演化式搜尋在自動演算法發掘上受到關注,但多數系統僅以程式碼與標量適應度追蹤進度。SeaEvo將自然語言策略提升為族群層級持續狀態,結合策略闡述、分層經驗檢索與景觀導航。實驗顯示在系統最佳化等開放任務上提升約21%效能,證明策略層面的持久化可增強演化搜尋的魯棒性與效率。

深度分析
這篇研究評估大型語言模型(LLM)在套用維基百科「中立觀點」(NPOV)規範時的能力,分別測試偏見偵測與中性化改寫兩項任務。研究發現模型在偏見偵測上準確度不佳,但在改寫上能移除多數被編輯者刪除的描述詞,呈現高召回低精確的特性,且常同時做出文法或風格改動。

深度分析
大型語言模型推動互動式HTML應用MiniApps成為新的人機介面。本文提出MiniAppBench與MiniAppEval,前者從真實平台萃取500題任務,強調遵循實世界原則與客製互動;後者以Playwright自動化執行意圖、靜態與動態三維評估。實驗顯示現有模型仍難穩定生成高品質MiniApps。

深度分析
研究以HBEE模擬器在預登記的五條件實驗中,讓100名LLM驅動代理人運行100個tick,模擬一名可適應行為的內鬼與不同防禦模式(cascade與blind UEBA)。核心做法是比較同儕懷疑圖(peer-suspicion graph)入度與每位代理人的UEBA排名,並以預先註明的統計檢定評估效果。

速報
背景:Lean與Mathlib為LLM輔助形式化推理的主流。方法:提出MathlibPR基準,從Mathlib4真實PR歷史擷取資料並設計分階段評估,測試多款大型語言模型與代理人。結果:模型難以區分可合併PR與僅通過建置但未合併的PR,MathlibPR提供審查輔助的監督信號。
