
aimock
aimock全方位 AI Mock 伺服器:支援 LLM、MCP 與向量資料庫測試
aimock 是一個在 GitHub 上活躍的開源專案,主打以單一套件、單一埠、零相依的方式,模擬 AI 應用在測試階段會呼叫到的各類服務。功能涵蓋 LLM API、多媒體生成、語音與影音處理、嵌入向量、向量資料庫、搜尋與重排序,以及 MCP 工具與代理間通訊(A2A)等。
aimock
aimock 是一個在 GitHub 上活躍的開源專案,主打以單一套件、單一埠、零相依的方式,模擬 AI 應用在測試階段會呼叫到的各類服務。功能涵蓋 LLM API、多媒體生成、語音與影音處理、嵌入向量、向量資料庫、搜尋與重排序,以及 MCP 工具與代理間通訊(A2A)等。

深度分析
AutoDFT 提出一套將大型語言模型(LLM)推入密度泛函理論(DFT)每個階段的閉環多代理人架構,藉由分層策略規劃與即時參數生成,讓系統能在執行中監測、復原並依證據修正計畫。該架構由七個專責代理人組成,從策略規劃、步驟參數化,到雙路監控、故障修復與步驟反思,將人類專家在工作流程中的判斷模組化。

速報
大語言模型在機器人形態搜尋常無可重用記憶。Auto‑Robotist將搜尋軌跡蒐成自然語言技能庫,記錄結構原型、正負規則與評估案例;搜尋時檢索技能以引導模型編輯並保留遺傳演算法探索路徑。實驗在多項EvoGym任務顯示5×5冷啟動搜尋改善,且技能可遷移至10×10,參照式轉移優於純GA。

深度分析
本文以「bugonomics」角度改寫並分析 ArXiv 文章,檢視大型語言模型(LLM)如 Anthropic Mythos 對漏洞發現與修補流程的經濟影響。作者主張,LLM 並非單純帶來更多可實務利用的零日,而是改變防禦端的成本結構:候選報告量激增、證據豐富的修補包更值錢,維護者的驗證、優先排序與發布成為瓶頸。

深度分析
作業系統核心形式驗證需精準規格,但手動撰寫昂貴。BODHI 以結構化 C→Python/Z3 翻譯指南擴充 few-shot prompt,分離前置檢查與後置狀態更新等關切點,並示範 15 類翻譯模式。實驗在 OSV-Bench 上顯著提升多款模型 Pass@1,顯示領域知識注入可實質改善規格生成。
深度分析
針對成長超線性且可能突變的時序資料,研究以分布式預測檢視大型語言模型表現。使用無污染模擬基準 FBSim、合成 SIR 及多項實證資料,比對連續量化分位與二元閾值評分。結果顯示:更高能力模型在包含尾部風險的長期預測上反而更差,主要因為上尾被過度外推。

MCP
Insight‑Link Pro 宣稱能把大型語言模型的回答綁定到實際程式倉庫與即時文件上,透過三階段執行管線:先探索並映射程式庫結構,接著擷取原始程式碼與線上文件或社群解答,最後綜合來源產出帶引用的回應。專案目標是把每一項主張對應到可驗證來源,降低模型憑空推論,讓開發者在除錯、文件查證與架構理解時取得可追溯的證據與上下文參考。

深度分析
都市路口長期仰賴號誌與相位控制管理車流。LISA 提出以大型語言模型做意圖仲裁,直接解析進場車輛宣告的意圖、優先級與節能偏好,並由確定性運動執行器轉為車輛速度建議,搭配 MAT 快取與預先仲裁以降低延遲。實驗顯示在多種流量條件下延遲與燃料消耗明顯降低。

深度分析
GrandGuard 提出首個系統性框架,專注於大型語言模型與高齡者互動的情境風險。研究建立包含50種細項風險的三層分類,並以10,404個標註範例構成嚴重度敏感基準,指出多款主流模型在高齡情境下逾半數案例處理不當。

大佬動態
SimonWillison宣布首版DatasetteAgent,這是一個為Datasette打造的可擴充人工智慧助手。它提供對資料的會話式查詢,並可透過外掛產生圖表。此發布標誌Datasette與作者多年LLM工具整合的初步成果,可能改變資料互動方式。

深度分析
研究發現對LLM的大量檢索下,表面>99%成功率可能等同隨機。論文提出Bits-over-Random(BoR)=log2(Pobs/Prand)衡量檢索選擇性,指當λ=K·R̄q/N超過3–5時選擇性崩潰,建議以BoR指引K與工具載入策略。
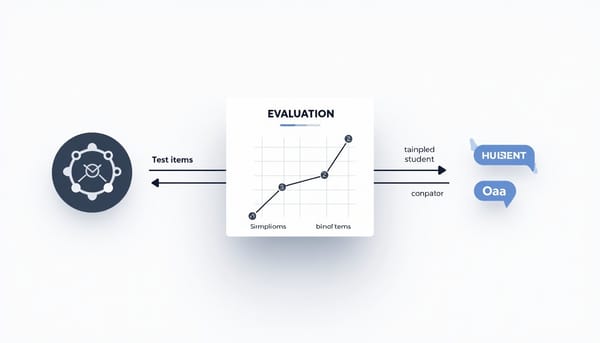
GEA
同一LLM生成試題、模擬回應並評分,提出Generative‑Evaluative Agreement(GEA)衡量生成與評分一致性。以皮爾森r與偏差量化,在24項Python OOP技能上得r=0.698、平均偏差+0.059,語法性技能一致性較好,設計性技能則接近零。