
深度分析
STORM:結合獎勵導向束搜索的步進式關鍵字優化提升 BM25 詞彙檢索效能
傳統詞彙檢索雖高效但常受詞彙不匹配限制,研究提出STORM以獎勵導向束搜索在生成關鍵字時即評估BM25檢索分數,僅保留高回饋分支。實驗顯示0.6B~8B模型在TREC DL與BEIR上可媲美或超越大型LLM改寫,同時保持與純BM25相當的檢索速度,且在18種語言零樣本轉移中表現優於多語言密集檢索。
深度分析
傳統詞彙檢索雖高效但常受詞彙不匹配限制,研究提出STORM以獎勵導向束搜索在生成關鍵字時即評估BM25檢索分數,僅保留高回饋分支。實驗顯示0.6B~8B模型在TREC DL與BEIR上可媲美或超越大型LLM改寫,同時保持與純BM25相當的檢索速度,且在18種語言零樣本轉移中表現優於多語言密集檢索。

深度分析
隨著機器人需要語意化環境,本研究探討使用大型語言模型自動將USD場景中的物件對應至本體類別,透過零樣本、免訓練的提示方式取得高達96%的精確匹配,顯示語意線索在本體對應上的關鍵作用。在125件廚房物件的測試中,模型在具描述性名稱下達到90%至96%相符率,較傳統字典與向量檢索均有明顯優勢。

深度分析
研究顯示,RAG生成因文件重複導致算力浪費,SIFT透過離線分析注意力不變性,只儲存高注意力位置的位元向量,於推論時稀疏計算,提升首 token 時間最高1.71倍,且精度損失不到1%。此方法減少KV快取磁碟讀寫,僅佔原始資料千分之一,適用於大型模型的即時服務。

深度分析
本篇深度報導探討代理式 AI 系統在執行過程中出現的變異現象,從基礎模型的 token 抽樣機制切入,說明隨機抽樣、決定性解碼與外部環境變化三大變異來源。

速報
研究團隊將大型語言模型(LLM)結合演化搜尋,成功找出在短碼長度下構造刪除更正碼的函式。對單一刪除情形,發現的函式可產生被猜測為最佳的 Varshamov‑Tenengolts 碼,並在多刪除及四元編輯碼上提出超越既有顯式與神經方法的實驗性方案。

深度分析
隨著語音助理朝全雙工互動發展,干擾會破壞LLM條件導致回應不穩。研究提出IRAF模組,以目標說話者與使用者音訊嵌入預測可靠性門檻,逐框調整融合權重。實驗在MS‑MARCO與InstructS2S-200K上顯示,回應品質與即時對話表現均有顯著提升。

深度分析
在自動化軟體開發中,代碼定位是瓶頸。研究提出FuseSearch,以學習式自適應平行執行降低冗餘,提升資訊密度。實驗顯示在SWE‑benchVerified上,檔案層F1提升至84.7%,搜尋速度加速93.6%。同時,使用回合數減少67.7%,代幣消耗下降68.9%,證明效率導向的訓練同時提升品質,此方法亦可延伸至其他程式碼搜尋任務,降低基礎設施需求。

深度分析
隨著大型語言模型需要透過模型上下文協議與外部工具互動,研究者針對MCP伺服器的執行時錯誤進行分類,採用自下而上開放編碼分析837個問題,形成11大類27子類的錯誤分類,調查顯示開發者普遍遭遇多數類別,為未來可靠性測試與故障注入提供基礎的重要。
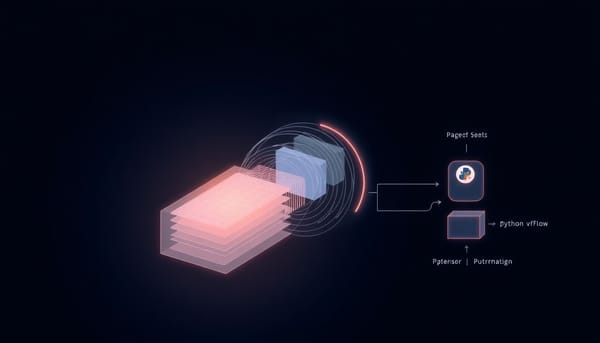
深度分析
隨著大型語言模型生成長度持續增加,稀疏注意力成為降低推論成本的關鍵。Vortex 以 Python 前端 vFlow 結合頁面式張量 vTensor,讓開發者與 AI 代理人快速設計、部署稀疏注意力,實測在 GLM‑4.7‑Flash 上提升 4.7 倍效能。此架構有望加速模型部署與自動化研究。

速報
Cocada 是一套以聊天驅動的多大型語言模型(LLM)協作框架,透過不同模型分工完成規劃、編碼、審查等工作,降低 token 消耗並提升交付品質。該專案在 GitHub 上獲得顯著關注,24 小時內星標快速上升,顯示開發者對多模型協同自動化的需求。

深度分析
本研究聚焦 Isabelle 中型別標註的完整性與最小化問題,透過人類與 LLM 代理人分別完成手寫與自動形式化,最終在 Isabelle/HOL 中生成三套等價證明,並以 AutoformBot 與 ProofWala 作對照,指出此類自動形式化可降低驗證成本、提升程式語言元理論的機械化,預期將推動 AI 輔助證明工具採用。

深度分析
隨著低資源語言缺乏對話式語音資料,研究提出利用大型語言模型產生情境對話並映射說話者屬性至TTS聲音,合成多說話者對話音檔。實驗在匈牙利BEA‑Dialogue基準上顯示,合成對話可提升辨識準確度,且在僅67小時真實資料與636小時合成資料的配置下,優於使用2700小時匈牙利語音的零樣本模型。